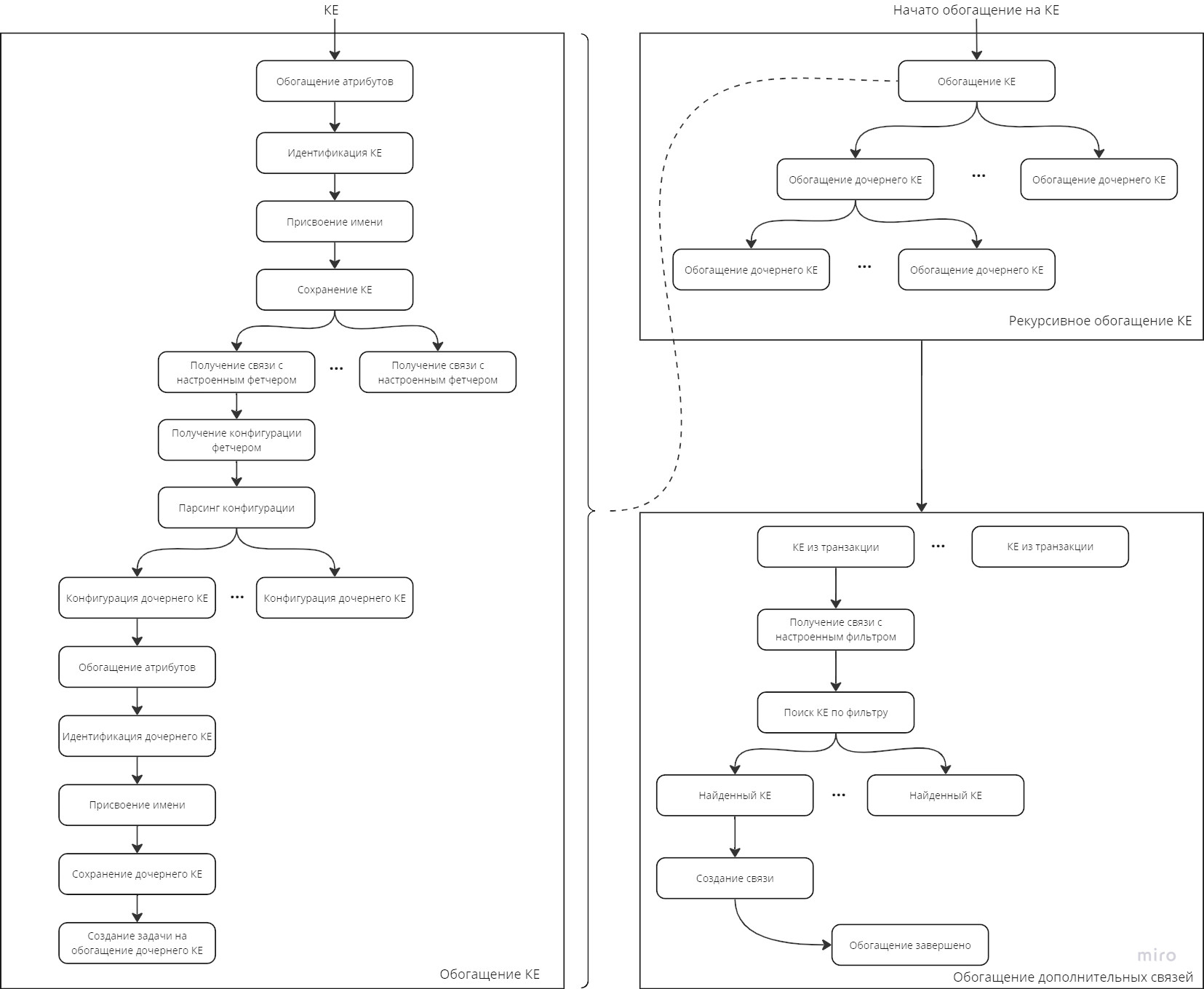
Обогащение
Общий процесс обогащения
Общий процесс обогащения атрибутов КЕ
Создание, изменение, удаление КЕ
Ключевые этапы при обогащении:
- Обогащение КЕ
- Обогащение атрибутов
- Идентификация и разрешение конфликтов
- Присвоение имени
- Очистка атрибутов
- Сохранение КЕ
- Обогащение связей
- Формирование связанных КЕ
- Обогащение атрибутов связанного КЕ
- Идентификация и разрешение конфликта
- Создание связи
- Удаление устаревших связей
- Рекурсивное обогащение
- Обогащение дополнительных связей
Запуск процесса обогащения
Процесс запускается для стартового КЕ и может рекурсивно продолжаться для связанных КЕ.
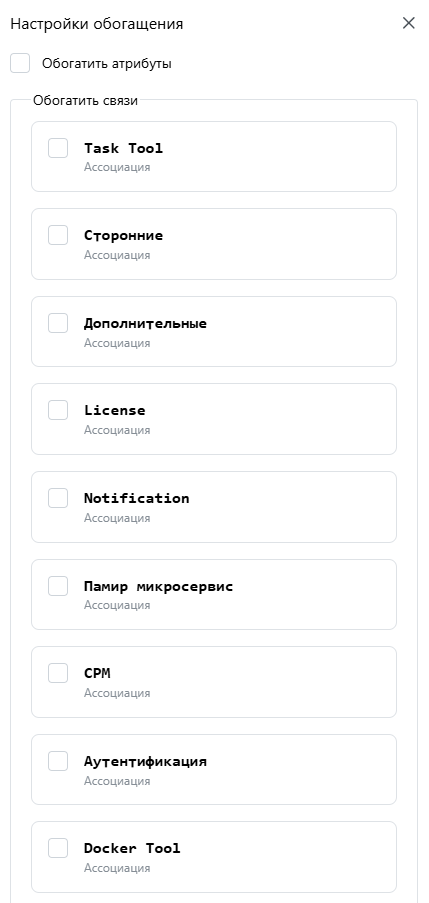
Настройки обогащения
При запуске можно выбрать параметры:
- Полное обогащение (по умолчанию) – обогащает атрибуты КЕ и все связанные КЕ.
- Обогащение только атрибутов – обновляет только атрибуты текущего КЕ.
- Выбор связей для рекурсивного обогащения – позволяет указать, какие связи следует обогащать.
Обогащение КЕ
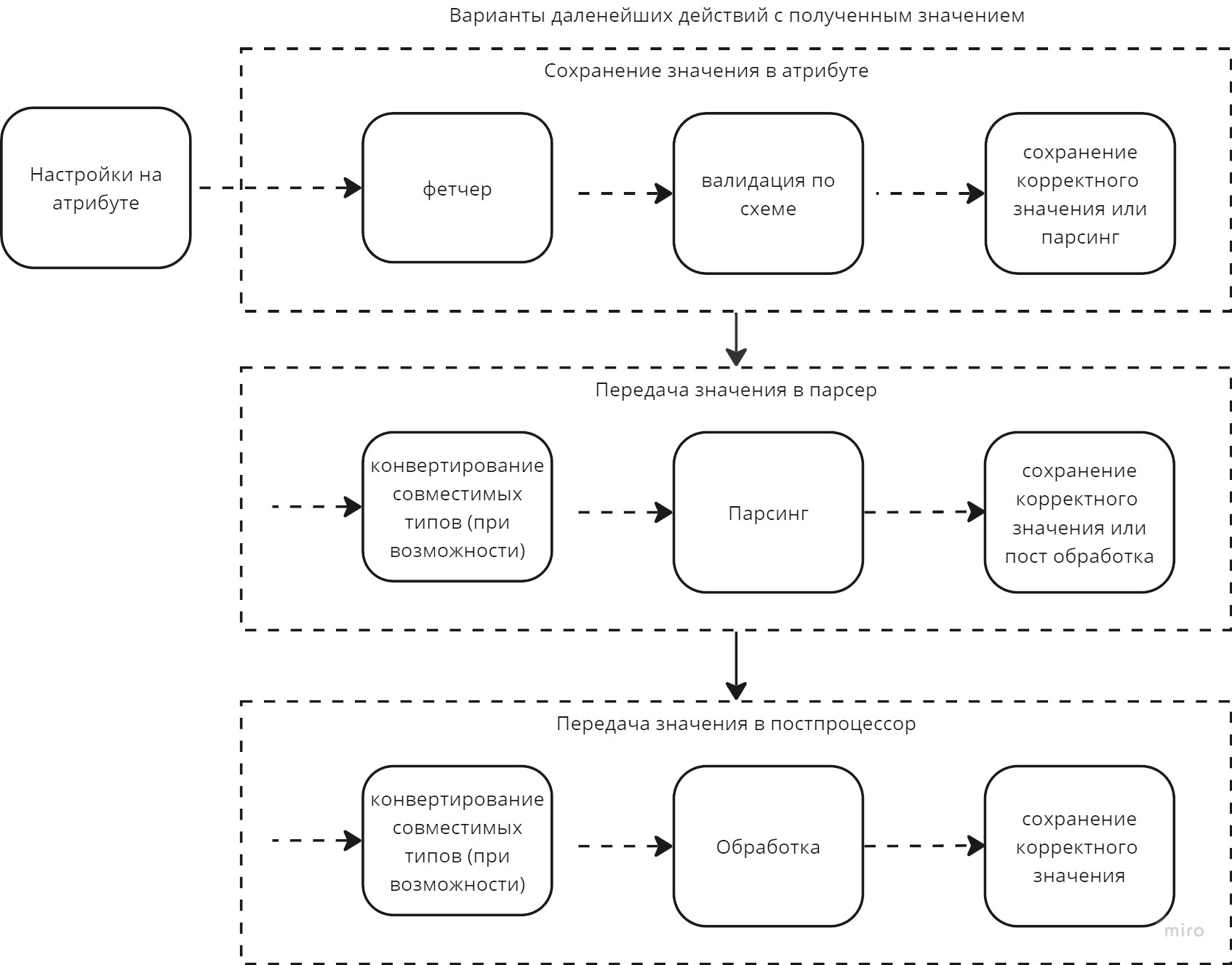
1. Обогащение атрибутов
Последовательность действий:
- Получение всех атрибутов текущего КЕ.
- Определение порядка обогащения с учетом зависимостей между атрибутами.
- Для каждого атрибута:
- Фетчер получает значение из внешнего источника.
- Парсер преобразует полученное значение.
- Результат приводится к типу атрибута и сохраняется.
Условия:
- Если фетчер не назначен, значение атрибута не изменяется.
- Если фетчер или парсер вернут
None, значение атрибута удаляется. - Если произошла ошибка в фетчере или парсере, значение остаётся без изменений.
2. Идентификация и разрешение конфликтов
После обновления атрибутов выполняется поиск аналогичных КЕ, существующих в системе:
- Система ищет КЕ, соответствующие текущему по идентификационным признакам.
- Поиск ведётся среди всех существующих КЕ, включая помеченные к удалению.
Если система не находит подходящих КЕ этап разрешения конфликта прерывается.
Если система находит один и более подходящих КЕ, выполняется разрешение конфликтов. Разрешение конфликтов оставляет только один КЕ. Объединение информации со всех КЕ выполняется следующим образом:
- Оставляется самый старый по времени создания КЕ.
- Если он был помечен к удалению — отметка снимается.
- Атрибуты у выжившего КЕ обновляются актуальными значениями.
- Все связи неудалённых КЕ присоединяются к выжившему КЕ.
- Остальные КЕ помечаются как удалённые.
5. Присвоение имени КЕ
- Имя КЕ устанавливается согласно правилам именования.
6. Очистка атрибутов
- Удаляются все атрибуты, у которых есть фетчер, но они не получили значения.
7. Сохранение КЕ
После всех этапов КЕ считается обогащённым и сохраняется в базу данных.
Обогащение связей
В конфигурации стартового КЕ может содержать информация о его составных частях. Составные части могут быть выделены в отдельные КЕ и связаны со стартовым КЕ.
Обогащение может создавать связи разных типов.
1. Формирование связанных КЕ
- Фетчер связи получает информацию о составных частях КЕ. Информация может быт получена из:
- атрибута стартового КЕ
- быть запрошена с объекта контроля
- Получив информацию о составных частях, Парсер должен превратить ее в список. Каждый элемент списка - это стартовая конфигурация, которая будет использоваться для создания связанного ЕК и запуска на нем обогащения.
- Для каждой конфигурации создаётся временный КЕ.
- На каждом временном КЕ продолжается обогащение. Стартовая конфигурация может использоваться:
- без сохранеиня с помощью фетчера
Receive data from config - сохранена в атрибут с помощью фетчера
Save data to attribute
- без сохранеиня с помощью фетчера
Вместо списка Парсер может вернуть единичный объект. В этом случае он будет использован без изменения для создания одного связанного КЕ.
2. Обогащение атрибутов связанного КЕ
Обогащение атрибутов связанного КЕ выполняется аналогично обогащению стартового КЕ.
3. Идентификация и разрешение конфликта
- Для каждого временного КЕ выполняется поиск аналогичных КЕ, существующих в системе:
- Если совпадений нет — временный КЕ создается фактически.
- При наличии совпадений — применяется алгоритм разрешения конфликта (см. выше).
- Атрибуты обновляются значениями из текущего обогащения.
4. Создание связи
- Создаётся связь между стартовым КЕ и найденным/созданным связанным КЕ.
5. Удаление устаревших связей
- Удаляются все существующие связи от стартового КЕ к тем, которые не были созданы в результате обработки.
- Если КЕ не может существовать без связей, он помечается как удалённый.
- Иначе — остаётся в системе, но без связи.
7. Рекурсивное обогащение
- После обогащения стартового КЕ и всех связанных с ним:
- Процесс обогащения запускается на каждом связанном КЕ.
- Действие повторяется рекурсивно.
- Все обогащённые КЕ добавляются в общий контекст обогащения.
Обогащение дополнительных связей
КЕ, созданные в ходе разных веток рекурсивного обогащения могут связываться:
- между собой
- с уже существующими в системе КЕ, не входящими в текущее обогащение
Для построения таких связей используется общий контекст обогащения. Для каждого КЕ в общем контексте обогащения:
- Выполняется поиск связанных КЕ по настроенным правилам.
Обогащение дополнительных связей выполняется после завершения рекурсивной стадии обогащения.
Механизм поиска
Механизм поиска формирует TQL-фильтр для поиска подходящих КЕ.
- Поиск может выполняться:
- local: только среди КЕ, участвовавших в текущем обогащении.
- global: среди всех КЕ в базе.
Предварительная очистка
- Перед поиском удаляются все существующие связи с текущим идентификатором связи между данным КЕ и другими.
Особенности
- Для связей типа композиция:
- Обогащение дополнительных связей не производится.
- Существующие КЕ не удаляются.
Создание связей
- После поиска между текущим КЕ и найденными создается связь.
Ключевые особенности этапов обогащения
Создание и изменение КЕ
Всякий раз когда создается новый КЕ или изменяются атрибуты существующего КЕ - выполняется идентификация и разрешение конфликтов.
- Идентификация с помощью правила находит совпадающие КЕ. При поиске учитываются значения атрибутов нового/изменяемого КЕ и других сохраненных КЕ этого типа.
- Если найден один и более совпадающий КЕ, то вместе с текущим КЕ они образуют конфликтную группу. Выполняется разрешение конфликтов.
Алгоритм разрешения конфликтов
- Из конфликтной группы выбирается самый старый по времени создания КЕ.
- Если этот КЕ был помечен к удалению, отметка снимается.
- Выполняется обновление атрибутов:
- Все атрибуты из конфликтных КЕ переносятся в выбранный КЕ
- Если атрибут присутствует в нескольких КЕ, сохраняется самое новое значение
- Связи неудалённых КЕ присоединяются к выжившему.
- Остальные конфликтные КЕ помечаются как удалённые.
Восстановление КЕ из удалённых
- Происходит автоматически, если:
- Конфликтный КЕ является самым старым.
- Он был помечен как удалённый.
- Отметка времени удаления устанавливается в
None.
Удаление КЕ
КЕ может быть удален:
- в ручную
- в процессе обогащения
Как принимается решение об удалении КЕ в процессе обогащения:
- При наличии конфликтов — все КЕ, кроме выжившего, помечаются как удалённые.
- При обработке связей — удаляются связи, которые не были созданы заново в ходе обогащения.
- Если КЕ не может существовать без связей — он помечается к удалению.
Удаление КЕ выполняется в два этапа:
- Пометка на удаление
- Физическое удаление из БД
1. Пометка на удаление
- В базе проставляется время удаления КЕ.
- Физически КЕ остаётся в базе данных.
- Используется для восстановления при конфликтах или дальнейших операциях.
2. Физическое удаление
- Происходит в фоновых задачах по расписанию.
- Удаляются данные из БД, включая атрибуты и связи.
Создание связи
Создание связи происходит после обогащения атрибутов связанного КЕ по результатам парсинга конфига связи.
Логика:
- Для каждого элемента конфига связи создаётся временный КЕ.
- Запускается его обогащение и идентификация.
- Создаётся связь между стартовым КЕ и найденным/созданным связанным КЕ.
Удаление связи
Удаление связи происходит после обработки всех элементов конфига связи.
Логика:
- Удаляются все существующие связи с таким же типом между текущим и целевыми КЕ.
- При удалении связи типа композиция удаляются все связанные КЕ.
- Удаляются только те связи, которые не были пересозданы в текущем цикле.
Изменение значения атрибута
1. Атрибут не имел значения → появилось новое значение
- Новое значение записывается в атрибут.
- Обновляется время последнего изменения атрибута.
2. Атрибут имел значение → появилось новое значение
- Старое значение заменяется на новое.
- Обновляется время последнего изменения атрибута.
3. Атрибут имел значение → значение исчезло (вернулось None)
- Если фетчер или парсер вернул
None, значение удаляется.
Атрибуты, у которых есть фетчер, но не участвовали в обогащении, также удаляются после завершения этапа.
Отслеживание процесса обогащения и решение проблем
Процесс обогащения данных в CMDB — это сложный механизм, который взаимодействует с различными источниками, обрабатывает данные и строит связи между конфигурационными единицами (КЕ). Чтобы вы могли полностью контролировать этот процесс, система фиксирует все ключевые события, которые происходят во время выполнения задач обогащения.
Эти события делятся на три типа:
- Уведомления (Notifications): Информационные сообщения о ходе выполнения задачи. Они сообщают о ключевых этапах, таких как начало, завершение отдельного шага или всей задачи. Это штатный режим работы.
- Предупреждения (Warnings): Сигналы о некритичных проблемах. Обогащение КЕ или ее части продолжается, но результат может быть неполным. Например, не удалось получить данные для одного из атрибутов, но остальные были успешно заполнены. На такие ситуации стоит обратить внимание, чтобы повысить качество данных.
- Ошибки (Errors): Сообщения о серьезных сбоях, которые помешали выполнить задачу или ее важную часть. Если вы видите ошибку, это означает, Rчто данные для КЕ не были обновлены или созданы корректно и требуется ваше вмешательство.
Где посмотреть результаты обогащения?
Вся история событий, связанных с обогащением, доступна в специальном разделе. Это ваш главный инструмент для диагностики и мониторинга качества данных в CMDB.
Путь в интерфейсе: Настройки → Типы КЕ → Итоги обогащения
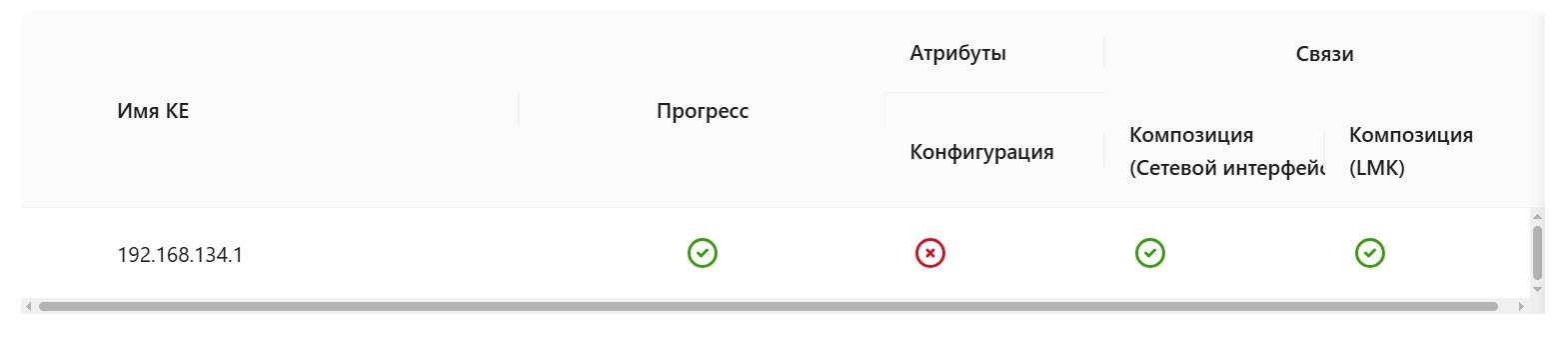
На этом экране вы найдете сводную статистику по последним запускам задач обогащения.
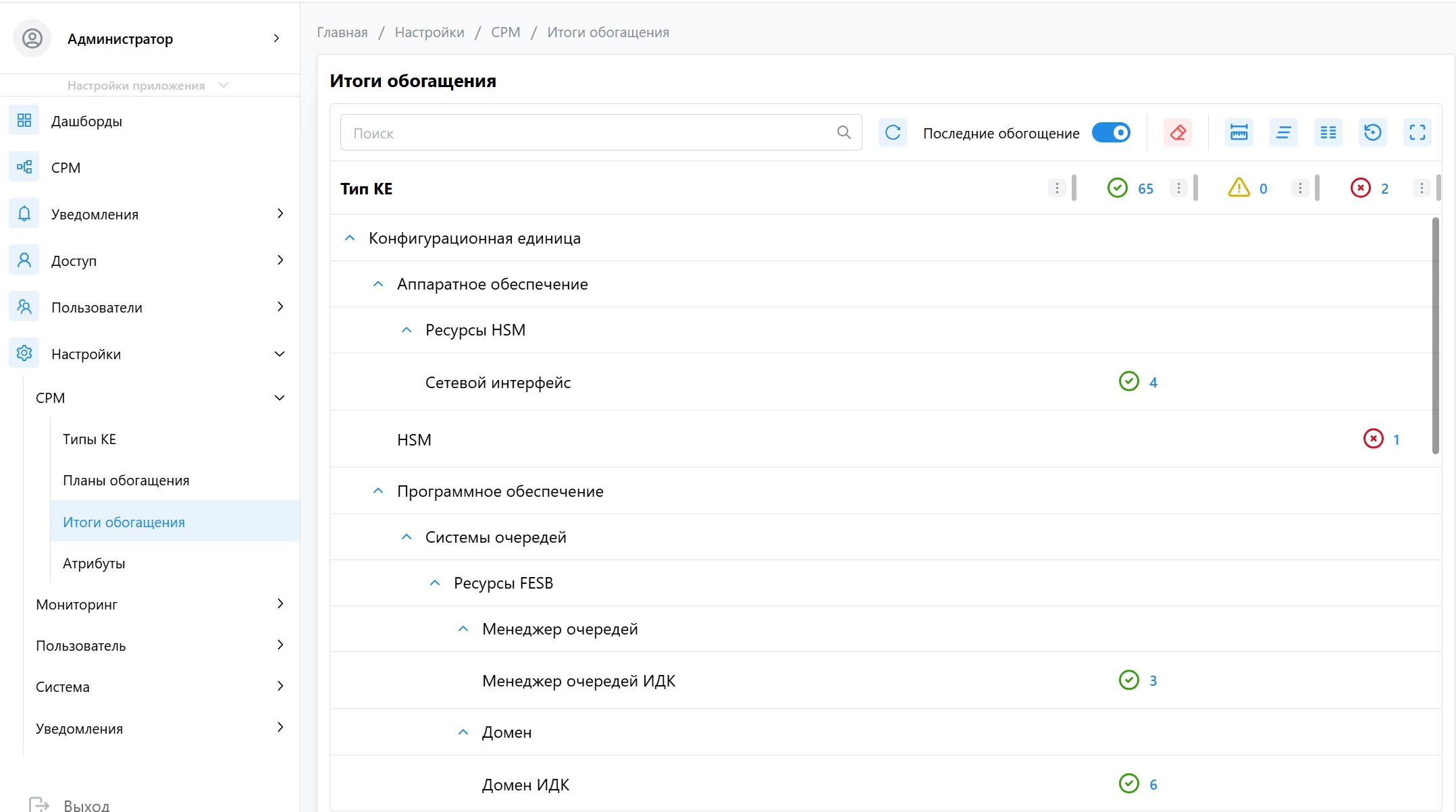
Результаты сгруппированы по типу источника (например, "Программное обеспечение", "LDAP", "Сторонние системы") и по статусу, который отражает итоговый результат обработки:
- ОК: Все КЕ из этой группы были обогащены успешно, без каких-либо проблем.
- Предупреждение: В процессе обогащения одной или нескольких КЕ возникли некритичные проблемы.
- Ошибка: При обработке одной или нескольких КЕ произошли критические сбои.
Важно: КЕ попадает в группу по наихудшему статусу. Если в ходе обогащения одной КЕ произошло 10 успешных уведомлений и всего одно предупреждение, итоговый статус этой КЕ будет «Предупреждение».
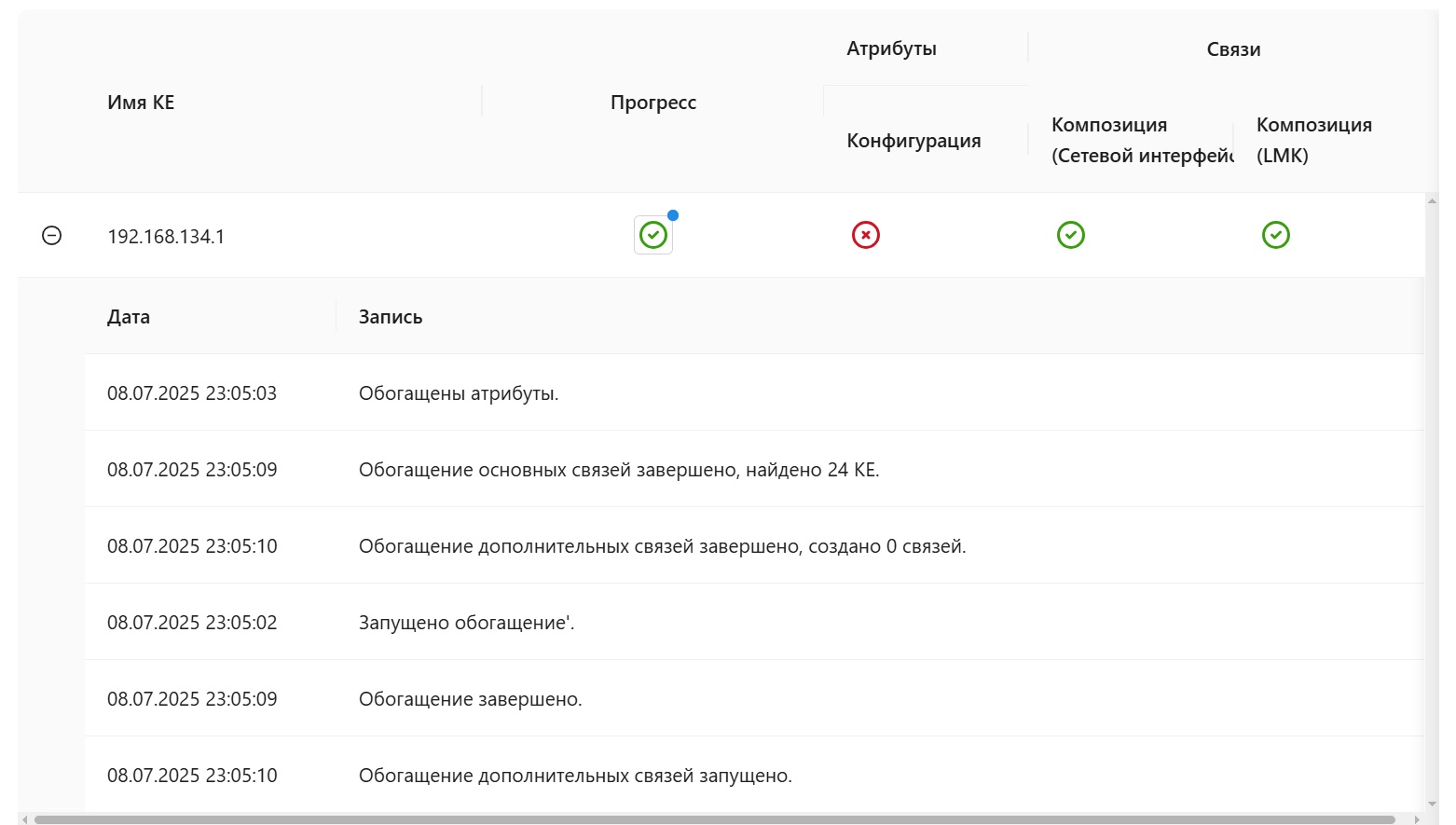
Детальный анализ событий
Чтобы понять, что именно произошло с конкретной КЕ, вы можете раскрыть нужную группу. Вы увидите список КЕ, сгруппированных по подкатегориям, которые соответствуют этапам обогащения:
- Прогресс: Общие события, отражающие жизненный цикл задачи (старт, завершение, глобальные ошибки).
- Атрибуты: Статусы, связанные с заполнением атрибутов КЕ.
- Связи: Статусы, связанные с поиском и созданием связей с другими КЕ.
Каждый элемент в этих подгруппах также отображает наихудший статус из всех событий, которые к нему относятся. Для получения полной картины просто кликните на интересующий вас элемент, чтобы увидеть подробный лог событий.
Типы событий и возможные причины
Ниже приведен подробный разбор событий, которые могут возникнуть на разных этапах обогащения.
1. Общий ход выполнения задачи (Статус "Прогресс")
- Уведомление:
Начало/завершение обогащения- Описание: Информационное сообщение о том, что задача для данной КЕ была запущена или успешно завершена.
- Предупреждение:
Повторная обработка КЕ в рамках одной задачи- Описание: Это происходит, когда одна и та же КЕ встречается в области обогащения несколько раз (например, сервер связан с несколькими приложениями, которые обогащаются одновременно). Система сообщает, что КЕ уже была обработана в рамках текущего запуска, чтобы избежать лишней работы.
- Ошибка:
Обнаружен цикл в вычислении атрибутов- Описание: Критическая ошибка конфигурации. Например, значение Атрибута 1 зависит от Атрибута 2, а значение Атрибута 2, в свою очередь, зависит от Атрибута 1. Это создает бесконечный цикл, и система прерывает обогащение, чтобы избежать зацикливания.
- Что делать: Проверьте формулы вычисления и зависимости атрибутов в настройках Типа КЕ.
- Ошибка:
Непредвиденный сбой при идентификации КЕилиНеобработанная ошибка- Описание: Общая ошибка, которая говорит о серьезном сбое на одном из этапов. В логе события будет доступна техническая информация (трейс ошибки), которую можно передать в службу поддержки для анализа.
2. Этап обогащения атрибутов (Статус "Атрибуты")
- Уведомление:
Атрибут [Имя атрибута] успешно заполнен- Описание: Данные для атрибута были успешно получены из источника и записаны в карточку КЕ.
- Предупреждение:
Не удалось получить данные для атрибута [Имя атрибута]- Описание: Система не смогла получить значение для указанного атрибута из внешнего источника. При этом обогащение остальных атрибутов продолжается.
- Возможные причины:
- Неверные учетные данные или права доступа к внешней системе.
- Сетевая недоступность источника данных.
- Данные отсутствуют в источнике (например, поле в CRM-системе пустое).
- Некорректные настройки фетчера (компонента, получающего данные).
- Предупреждение:
Обнаружен дубликат КЕ после обогащения атрибутов- Описание: После того как система заполнила атрибуты из источника, она провела идентификацию и обнаружила, что обновляемая КЕ теперь полностью совпадает с другой, уже существующей в CMDB. Это сигнал о возможном дублировании данных.
- Ошибка:
Некорректный формат данных для атрибута [Имя атрибута]- Описание: Данные из источника были получены, но их не удалось записать, так как их формат не соответствует типу атрибута в CMDB (например, пытаемся записать текст "три" в числовое поле).
- Что делать: Проверьте, какие данные приходят из источника, и при необходимости скорректируйте их с помощью правил трансформации или измените тип атрибута в CMDB.
3. Этап построения связей (Статус "Связи")
На этом этапе система пытается найти или создать связанные КЕ на основе полученных данных.
- Уведомление:
Обогащение связи [Название связи] завершено- Описание: Все операции по построению одной или всех связей для данной КЕ успешно завершены.
- Предупреждение:
Неоднозначная идентификация связанных КЕ- Описание: Система искала связанную КЕ по заданным правилам и нашла несколько подходящих кандидатов. Так как результат неоднозначен, система не стала автоматически создавать связь, чтобы не нарушить целостность данных.
- Что делать: Уточните правила идентификации для связанного Типа КЕ, чтобы поиск давал уникальный результат.
- Описание: Система искала связанную КЕ по заданным правилам и нашла несколько подходящих кандидатов. Так как результат неоднозначен, система не стала автоматически создавать связь, чтобы не нарушить целостность данных.
- Предупреждение:
Ошибка при заполнении атрибутов связи- Описание: Связь между КЕ была установлена, но не удалось заполнить ее атрибуты (если они есть).
- Ошибка:
Ошибка получения/парсинга конфигурации для связи- Описание: Система не смогла получить или обработать правила, по которым нужно строить связь. Чаще всего это говорит о некорректной настройке в конфигурации обогащения.
- Ошибка:
Ошибка создания КЕ по связи- Описание: Правила предписывали создать новую связанную КЕ, но в процессе ее создания произошел сбой (например, из-за нехватки данных для обязательных атрибутов новой КЕ).
- Ошибка:
Ошибка при подготовке фильтра для поиска КЕ- Описание: Система не смогла сформировать корректный запрос для поиска связанных КЕ на основе имеющихся данных и настроек. Проверьте правила построения связей.
Использование этого инструмента позволит вам не только оперативно реагировать на проблемы, но и проактивно улучшать качество и полноту данных в вашей CMDB.
События обогащения
В ходе процесса обогащения генерируются события. К событиям можно получить доступу в RabbitMQ.
Пользовательские события
1. Начало обогащения (Started)
Назначение: Событие возникает при старте процесса обогащения конфигурационной единицы (КЕ).
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.enrichment.Started
Время публикации: В момент начала операции обогащения
{
"notification_id": "UUID", // Уникальный идентификатор для доставки уведомления пользователю
"ci_id": "UUID", // Идентификатор обогащаемой конфигурационной единицы
"ci_type_name": "string" // Наименование типа конфигурационной единицы
}
2. Завершение обогащения (Finished)
Назначение: Событие возникает при завершении процесса обогащения, содержащее итоговую статистику.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.enrichment.Finished
Время публикации: После окончания всех операций обогащения
{
"ci_count": 0, // Общее количество обработанных КЕ
"status": "string", // Наихудший статус среди всех обработанных КЕ
"duration": 0 // Общее время выполнения обогащения в секундах
}
События статистики
1. CIEnrichmentSuccess
Назначение: Информирует об успешном завершении этапа обогащения конфигурационной единицы.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.CIEnrichmentSuccess
Время публикации:
- При начале/окончании обогащения КЕ
- После обогащения атрибутов
- После обработки основных связей
- При начале/окончании обработки дополнительных связей
{
"message": "string", // Текст информационного сообщения
"msg_vars": {}, // Переменные для формирования сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"status": "OK", // Статус выполнения
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
2. CIEnrichmentError
Назначение: Содержит информацию о критических ошибках в процессе обогащения.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.CIEnrichmentError
Время публикации:
- При критических ошибках обогащения
- При ошибках подготовки фильтров для поиска КЕ
{
"message": "string", // Текст сообщения об ошибке
"msg_vars": {}, // Переменные для сообщения
"ci_id": "UUID", // Идентификатор проблемной КЕ
"ci_type_name": "string", // Тип КЕ
"status": "ERROR", // Статус ошибки
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
3. CIEnrichmentWarning
Назначение: Предупреждения о не критических проблемах.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.CIEnrichmentWarning
Время публикации: При замене обогащенного КЕ ранее существовавшим
{
"message": "string", // Текст предупреждения
"msg_vars": {}, // Переменные для сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"status": "WARNING", // Статус предупреждения
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
События обогащения атрибутов
1. AttrEnrichmentSuccess
Назначение: Подтверждение успешного обогащения атрибута.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.AttrEnrichmentSuccess
Время публикации: После сохранения значения атрибута
{
"message": "string", // Текст сообщения
"msg_vars": {}, // Переменные сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"attr_name": "string", // Наименование атрибута
"status": "OK", // Статус успеха
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
2. AttrEnrichmentWarning
Назначение: Предупреждение о проблемах получения данных для атрибута.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.AttrEnrichmentWarning
Время публикации: При невозможности получить данные для атрибута
{
"message": "string", // Текст предупреждения
"msg_vars": {}, // Переменные сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"attr_name": "string", // Наименование атрибута
"status": "WARNING", // Статус предупреждения
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
3. AttrEnrichmentError
Назначение: Ошибки сохранения данных в атрибуте.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.AttrEnrichmentError
Время публикации: При неудачном сохранении значения атрибута
{
"message": "string", // Текст ошибки
"msg_vars": {}, // Переменные сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"attr_name": "string", // Наименование атрибута
"status": "ERROR", // Статус ошибки
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
События обогащения связей
1. LinkEnrichmentSuccess
Назначение: Уведомление об успешном создании связи.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.LinkEnrichmentSuccess
Время публикации: После создания связи
{
"message": "string", // Текст сообщения
"msg_vars": {}, // Переменные сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"cit_link_id": "UUID", // Идентификатор связи
"status": "OK", // Статус успеха
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
2. LinkEnrichmentWarning
Назначение: Предупреждения о проблемах при обработке связей.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.LinkEnrichmentWarning
Время публикации:
- При попытке повторного обогащения
- При объединении КЕ
- При ошибках заполнения атрибутов связи
{
"message": "string", // Текст предупреждения
"msg_vars": {}, // Переменные сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"cit_link_id": "UUID", // Идентификатор связи
"status": "WARNING", // Статус предупреждения
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
3. LinkEnrichmentError
Назначение: Критические ошибки обработки связей.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.LinkEnrichmentError
Время публикации:
- При ошибках парсинга конфигурации
- При проблемах получения конфигурации
- При неудачном создании КЕ
{
"message": "string", // Текст ошибки
"msg_vars": {}, // Переменные сообщения
"ci_id": "UUID", // Идентификатор КЕ
"ci_type_name": "string", // Тип КЕ
"cit_link_id": "UUID", // Идентификатор связи
"status": "ERROR", // Статус ошибки
"task_id": "UUID", // Идентификатор задачи
"root_task_id": "UUID" // Идентификатор корневой задачи
}
4. AdditionalLinkFinished
Назначение: Уведомление о завершении обработки дополнительных связей.
Topic: SRM_EXCHANGE
Ключ маршрутизации: srm.statistic.AdditionalLinkFinished
Время публикации: После обработки всего дерева связей
{
"message": "string", // Текст сообщения
"msg_vars": {}, // Переменные сообщения
"root_task_id": "UUID" // Идентификатор корневой задачи
}
Обогащение по расписанию
Описать настройку обогащения по расписанию
Уведомления по время обогащения
Описать какие уведомления генерируются в процессе обогащения
Фетчеры
Фетчер - это компонент или модуль, который отвечает за получение (fetch) данных из внешних источников.
Наследование параметров фетчеров
Благодаря наследованию CMDB выполняет автоматическую привязку атрибутов в дереве ТКЕ. Однако, для обогащения сами атрибуты привязать недостаточно. На них нужно настроить фетчеры. Настройка фетчеров подчиняется правилам наследования. Поведение наследования зависит от того в каком месте иерархической цепочки выполняется настройка. В общем виде правила наследования выглядят следующим образом:
- Настройка фетчера распространяется на все атрибуты дочерних ТКЕ
- На дочернем ТКЕ фетчер может быть переопределен
- Переопределение может быть удалено, фетчер восстановит настройку родителя
- Фетчер самостоятельно не может перейти из настроенного/переопределенного состояния в унаследованное, даже если его настройки совпадают с родительским фетчером
Настройка фетчера на корневом атрибуте
Настройка фетчера на атрибуте корневого ТКЕ приведет к тому, что настройка распространится на все
Получить данные из атрибута
Предназначен для получения данных из значения атрибута КЕ.
Настраиваемый параметр: атрибут из которого взять данные - наименование атрибута ТКЕ.
Получить данные из конфигурации
Предназначен для получения конфигурации КЕ во время обогащения.
Сохранить значение в атрибут
Предназначен для заполнения атрибута КЕ определенным значением.
Настраиваемый параметр: данные, которые нужно записать в атрибут - строка.
Выполнить HTTP GET запрос
Предназначен для получения данных по HTTP. Настраиваемые параметры:
параметры запроса- строка;проверить TLS сертификат сервера- флаг включающий проверку TLS сертификата сервера;использовать ТКЕ для подстановки данных из атрибутов-Не использоватьили наименование ТКЕ;имя хоста- строка или наименование атрибута ТКЕ;порт- число или наименование атрибута ТКЕ;логин- строка или наименование атрибута ТКЕ;пароль- строка или наименование атрибута ТКЕ;путь- строка или наименование атрибута ТКЕ;
Выполнить SSH команду
Предназначен для получения данных по ssh. Настраиваемые параметры:
команда выполняемая на устройстве- строка;использовать ТКЕ для подстановки данных из атрибутов-Не использоватьили наименование ТКЕ;имя хоста- строка или наименование атрибута ТКЕ;порт- число или наименование атрибута ТКЕ;логин- строка или наименование атрибута ТКЕ;пароль- строка или наименование атрибута ТКЕ;цифровой отпечаток- строка или наименование атрибута ТКЕ;
Опросить DionisNX
Предназначен для взаимодействия с DionisNX по ssh. Настраиваемые параметры:
действие-Получить конфигурациюилиВыполнить команду;конфигурации-runningилиstartup;команда- строка или наименование атрибута ТКЕ;использовать ТКЕ для подстановки данных из атрибутов-Не использоватьили наименование ТКЕ;имя хоста- строка или наименование атрибута ТКЕ;порт- число или наименование атрибута ТКЕ;логин- строка или наименование атрибута ТКЕ;пароль- строка или наименование атрибута ТКЕ;цифровой отпечаток- строка или наименование атрибута ТКЕ;
Отпечаток ключа
Предназначен для получения ssh отпечатка. Настраиваемые параметры:
использовать ТКЕ для подстановки данных из атрибутов-Не использоватьили наименование ТКЕ;имя хоста- строка или наименование атрибута ТКЕ;порт- число или наименование атрибута ТКЕ;
Получить авторизационные данные из запроса
Предназначен для получения авторизационных данных из HTTP запроса. Настраиваемые параметры:
формат HTTP запроса-JavaScript форматилиYaml формат;проверить TLS сертификат сервера- флаг включающий проверку TLS сертификата сервера;данные HTTP запроса для авторизации- текст;данные HTTP запроса для проверки/продления актуальности данных- текст;
Пример параметра данные HTTP запроса для авторизации в JavaScript формате:
fetch("http://example.com/test?id=8&name=t", {
"headers": {
"content-type": "application/json",
"cookie": "params=1; session=123"
},
"body": "{\"arguments\":{\"attribute_name\":\"raw_configuration\"}}",
"method": "PUT"
});
Пример параметра данные HTTP запроса для проверки/продления актуальности данных в Yaml формате:
url: http://example.com/test
params:
id: 8
name: t
headers:
content-type: application/json
cookie: params=1; session=123
body:
arguments:
attribute_name:raw_configuration
method: PUT
Правила заполнения параметров
Поле для параметров данные HTTP запроса для авторизации и данные HTTP запроса для проверки/продления актуальности данных поддерживают шаблонизатор jinja.
Используются следующие правила:
[%- начало блока;%]- конец блока;[#- начало коментария;#]- конец коментария;[[- начало переменной;]]- конец переменной.
Поддерживаются следующие конструкции:
[[ attributes.<имя_атрибута> ]]- ссылка на значение атрибута;[[ composition.<имя_ТКЕ>.attributes.<имя_атрибута> ]]- ссылка на значение атрибута композирующего КЕ;[[ fields.ci_id ]]- ссылка на идентификатор текущего КЕ;[[ fields.ci_type_name ]]- ссылка на имя ТКЕ текущего КЕ;[[ fields.comp_ci_id ]]- ссылка на идентификатор композирующего КЕ.
Поддерживаются следующие ключи:
url- только в Yaml формате;params;headers;body;method;
Ключ method поддерживает следующие значения:
GET;OPTIONS;HEAD;POST;PUT;PATCH;DELETE.
Выполнить HTTP запрос
Предназначен для получения данных по HTTP. Настраиваемые параметры:
формат HTTP запроса-JavaScript форматилиYaml формат;запомнить возвращенную cookie в глобальном хранилище- флаг;проверить TLS сертификат сервера- флаг включающий проверку TLS сертификата сервера;данные HTTP запроса для авторизации- текст, поддерживает шаблонизатор jinja аналогично фетчеруПолучить авторизационные данные из запроса;
Cell tower fetcher
Предназначен для получения усреднённых координат на основании данных о вышках сотовой связи. Входные данные представляют собой список объектов, содержащих информацию о вышках, включая их координаты и идентификаторы.
Настраиваемый параметр: атрибут из которого взять данные - наименование атрибута ТКЕ, из которого будут извлекаться данные.
Данные в атрибуте должны быть представлены в виде списка объектов со следующими полями:
act- (опционально) активность;mcc- (опционально) код страны;mnc- (опционально) код оператора;area- (опционально) код зоны;cell- (опционально) код ячейки;lon- (опционально) долгота вышки;lat- (опционально) широта вышки; Все поля не обязательны, но хотя бы одно из них должно быть заполнено. Лишние поля игнорируются.
Пример json схемы для атрибута:
{
"type": "array",
"items":{
"type": "object",
"properties": {
"act": {
"type": "string"
},
"mcc": {
"type": "integer"
},
"mnc": {
"type": "integer"
},
"area": {
"type": "integer"
},
"cell": {
"type": "integer"
},
"lon": {
"type": "number"
},
"lat": {
"type": "number"
}
}
}
}
Пример данных в атрибуте:
[{
"act": 123,
"mcc": 123,
"mnc": 123,
"area": 123,
"cell": 123,
"lon": 123.123,
"lat": 123.123
}]
В результате работы фетчер возвращает следующую структуру:
{
"lat": 123.23,
"lon": 123.23,
"precision": 10,
}
Логика работы фетчера
-
Группировка данных: Входные данные группируются по уровню точности, от более точных к менее точным.
-
Усреднение координат: Усреднение выполняется только в пределах одной группы. Выбирается группа с наивысшей точностью. Внутри группы координаты берутся из базы данных вышек с учетом имеемой информации о вышке в текущей группе. Чем меньше информации о вышке тем больше вариантов получится при сопоставлении с базой данных, тем меньше точность результата.
-
Определение точности: Точность результата зависит от полноты данных о вышке. Значение точности указывается в поле precision.
Уровни точности
- 10: Используются поля lon и lat.
- 9: Используются поля act, mcc, mnc, area, cell.
- 8: Используются поля mcc, mnc, area, cell.
- 7: Используются поля act, mcc, mnc, area.
- 6: Используются поля mcc, mnc, area.
- 5: Используются поля act, mcc, mnc.
- 4: Используются поля mcc, mnc.
Примеры работы
- Пример 1:
Входные данные:
[{
"act": 123,
"mcc": 123,
"mnc": 123,
"area": 123,
"cell": 123,
"lon": 123.123,
"lat": 123.123
}]
Результат:
{
"lat": 123.123,
"lon": 123.123,
"precision": 10,
}
- Пример 2:
Входные данные:
[{
"act": 123,
"mcc": 123,
"mnc": 123,
"area": 123,
"cell": 123,
}]
Результат(координаты получены из базы данных вышек):
{
"lat": 123.123,
"lon": 123.123,
"precision": 9,
}
Требования к данным
Для работы фетчера необходима база данных координат вышек сотовой связи. Архив с координатами сервера доступен по ссылке https://nexus.pamir.int/#browse/browse:pamir-configs:cell_towers.sqlite.
Настройки окружения
- Скачайте архив и разместите его в локальном хранилище.
- Пробросьте архив в контейнер
celery, указав путь к файлу в переменной окруженияCELL_TOWERS_SQLITE_PATHПо умлочанию (без указания переменной) файл ищется по пути/opt/tenax-it/cell_towers/cell_towers.sqlite.
Пример проброса архива в контейнер (если архив с вышками лежит в папке ./data/cell_towers):
# docker-compose.celery.app.yml в контейнере:
- type: bind
source: ./data/cell_towers
target: /opt/tenax-it/cell_towers
Требования к данным
Для работы фетчера необходима база данных координат вышек сотовой связи. Архив с координатами сервера доступен по ссылке https://nexus.pamir.int/#browse/browse:pamir-configs:cell_towers.sqlite.
Настройки окружения
- Скачайте архив и разместите его в локальном хранилище.
- Пробросьте архив в контейнер
celery, указав путь к файлу в переменной окруженияCELL_TOWERS_SQLITE_PATHПо умлочанию (без указания переменной) файл ищется по пути/opt/tenax-it/cell_towers/cell_towers.sqlite.
Пример проброса архива в контейнер (если архив с вышками лежит в папке ./data/cell_towers):
# docker-compose.celery.app.yml в контейнере:
- type: bind
source: ./data/cell_towers
target: /opt/tenax-it/cell_towers
Выполнить PromQL запрос
Предназначен для получения данных от Prometheus. Настраиваемые параметры:
атрибут из которого взять данные-Использовать литеральное значениеили наименование атрибута ТКЕ;значение- текст;проверить TLS сертификат сервера- флаг включающий проверку TLS сертификата сервера;
Парсеры
Парсеры предназначены для обработки значений атрибутов полученных фетчерами.
Наследование параметров парсеров
Наследование параметров парсеров выполняется аналогично фетчерам
JQ parser
Парсер предназначен для извлечения данных из JSON конфигурации, при помощи языка jq. Аргументы парсера - это список JQ выражений и методов. Парсер поочереди выполняет выражения, до первого совпадения. Аргументы парсера:
выражение- строка описывающая JQ выражение, поддерживает шаблонизатор jinja;метод поиска-текст,все совпаденияилипервое совпадение;постпроцессоры- список постпроцессоров.
Например, корневым элементом конфигурации является список:
[1, 2, 3]
В этом случае выражение [# jinja2 comment #] .[]+5 вернет:
6\n7\n8- результат методатекст;[6, 7, 8]- результат методавсе совпадения;6- результат методапервое совпадение.
JSON
Парсер предназначен для извлечения данных из JSON конфигурации, при помощи библиотеки python objectpath. Аргументы парсера:
выражение- строка описывающая Objectpath выражение;группировать по- поле по которому происходит группировка, например@.field. Группа представляет собой массив. Задается в виде фильтра для json path, который можно применить после выполнения выражения.постпроцессоры- список постпроцессоров.
Например, корневым элементом конфигурации является объект:
{
"str_val": "asc",
"int_val": 123,
"str_list_val": ["asc","desc"],
"dt_val": "2023-10-19 12:00:00",
"bool_val": true,
"jb_val": {"val": true, "list": ["asc",123,false]},
"obj_list": [{"key": "one", "val": "first"}, {"key": "two", "val": "second"}]
}
В этом случае выражения могут быть следующие:
$.bool_val- выбор элемента по ключу, вернет результатtrue;$.obj_list[0].val- выбор элемента списка по индексу, вернет результатfirst;$.obj_list[@.key is 'one'][0].val- выбор элемента списка по условию, вернет результатfirst.
Например, корневым элементом конфигурации является список:
[
{"key": "one", "val": "first"},
{"key": "two", "val": "second"}
]
В этом случае выражения могут быть следующие:
$*[0].val- выбор элемента списка по индексу, вернет результатfirst;$*[@.key is 'one'][0].val- выбор элемента списка по условию, вернет результатfirst.
Цепочка регулярных выражений
Парсер поочереди выполняет регулярные выражения, результаты помещенные в группы по одному передаются на вход следующего регулярного выражения. Аргументы парсера:
список регулярных выражений- список регулярных выражений, поддерживаемых python;постпроцессоры- список постпроцессоров.
Регулярное выражение с именованными группами
Парсер поочереди выполняет регулярные выражения. В регулярных выражениях можно задать имена групп, результаты разбора вернутся в виде списка словарей, ключами которых будут заданные имена групп. Если имена групп не заданы, вернется список строк. Аргументы парсера:
список регулярных выражений- список регулярных выражений с именованными группами, поддерживаемых python.
Например, для конфигурации списка правил доступа:
ip access-list no-web
deny tcp dport www
deny tcp sport www
permit icmp
Список регулярных выражений может быть таким:
^ (?P<rule>\S+) (?P<proto>\S+) (?P<dest>\S+) (?P<port>\S+)$- выбираем правила из 4 слов;^ (?P<rule>\S+) (?P<proto>\S+)$- выбираем правила из 2 слов.
Регулярное выражение
Парсер находит вхождения для регулярного выражения. Аргументы парсера:
регулярное выражение- регулярное выражение, поддерживаемое python;метод поиска-все совпадения (с номерами строк),все совпаденияилипервое совпадение;тип разделителя после номера строки-пробелилилитеральное значение;разделитель номера строки- строка;постпроцессоры- список постпроцессоров.
Постпроцессоры
Постпроцессоры предназначены для обработки значений атрибутов полученных парсерами.
True постпроцессор
Постпроцессор предназначен для сравнения полученного парсером результата с ожидаемым значением.
Если результат парсера совпадает с ожидаемым значением, то возвращается True (истина), иначе результат возвращается без изменений.
Аргументы постпроцессора:
ожидаемое значение- строка.
False постпроцессор
Постпроцессор предназначен для сравнения полученного парсером результата с ожидаемым значением.
Если результат парсера совпадает с ожидаемым значением, то возвращается False (ложь), иначе результат возвращается без изменений.
Аргументы постпроцессора:
ожидаемое значение- строка.
Постпроцессор строки времени
Постпроцессор предназначен для преобразования строки времени в строку времени в соответствии с аргументами. Аргументы постпроцессора:
шаблон- возвращаемый формат, поддерживаемый python, например%Y-%m-%d %H:%M:%S;временная зона- временная зона заданная строкой форматаHH:MM:00, где HH - часы, а ММ - минуты;временной сдвиг-плюсилиминус. Особенности работы: Аргументвременная зоназаполнять не обязательно. В этом случае применяется временная зона сервера Памир и аргументвременной сдвигне обрабатывается. Например:- обрабатываемая строка:
2025-05-09 11:00:00 - шаблон:
%Y-%m-%d %H:%M:%S - временная зона: незаполнено
- результат:
2025-05-09T11:00:00+03:00Если в шаблоне используются параметры временной зоны%Zили%z, и заполнен аргументвременная зона, то в обработке будет использоваться значение аргументавременная зона. Например: - обрабатываемая строка:
2025-05-09 11:00:00 UTC +0500 - шаблон:
%Y-%m-%d %H:%M:%S %Z %z - временная зона:
03:00:00 - временной сдвиг:
плюс - результат:
2025-05-09T11:00:00+03:00
Постпроцессор метки времени
Постпроцессор предназначен для преобразования времени из секунд или миллисекунд прошедших с 01.01.1970 в строку формата YYYY-MM-DD HH:MM:SS+HH:MM.
Аргументы постпроцессора:
единица измерения-секундыилимиллисекунды.
Постпроцессор подстановки значения
Постпроцессор предназначен для замены полученного парсером результата, на значение из списка пар "ключ": "значение".
Если результат парсера совпадает с ключом в списке, то возвращается соответствующее ключу значение, иначе результат возвращается без изменений.
Аргументы постпроцессора:
ключ- ожидаемое значение;значение- новое значение.