Виджеты
Индикаторы здоровья
Виджет Индикаторы здоровья предназначен для визуализации текущего состояния индикаторов здоровья конфигурационных единиц (КЕ) в рамках заданной области видимости TQL.
![]()
Основные функции и особенности
- Отображение актуальных состояний ИЗ
- Виджет выводит все индикаторы здоровья, связанные с КЕ, в соответствии с областью видимости TQL.
- Каждый индикатор отображается в виде блока с цветовой индикацией (например, зелёный – норма, красный – критическая ошибка).
- Детализация состояния ИЗ
- При нажатии на блок индикатора открывается подробная информация о его текущем состоянии, включая:
- Текущий статус (OK, Warning, Critical).
- Описание проблемы (если есть).

Источник данных
Данные для виджета берутся из:
- Индикаторов здоровья, привязанных к КЕ.
- TQL-запроса, определяющего область видимости (какие КЕ и их ИЗ должны отображаться).
Виджет поддерживает несколько вариантов группировки:
- Вся область видимости TQL – отображение всех ИЗ в рамках запроса.
- Узлы TQL – группировка по узлам топологии.
- Конфигурационные единицы (КЕ) – группировка по отдельным КЕ.
В зависимости от выбранного режима, данные распределяются по вкладкам, соответствующим типам КЕ или узлам.
Виджет позволяет скрывать или выделять определённые КЕ для более удобного анализа. Поддерживает стандартные механизмы фильтрации.
История индикаторов здоровья
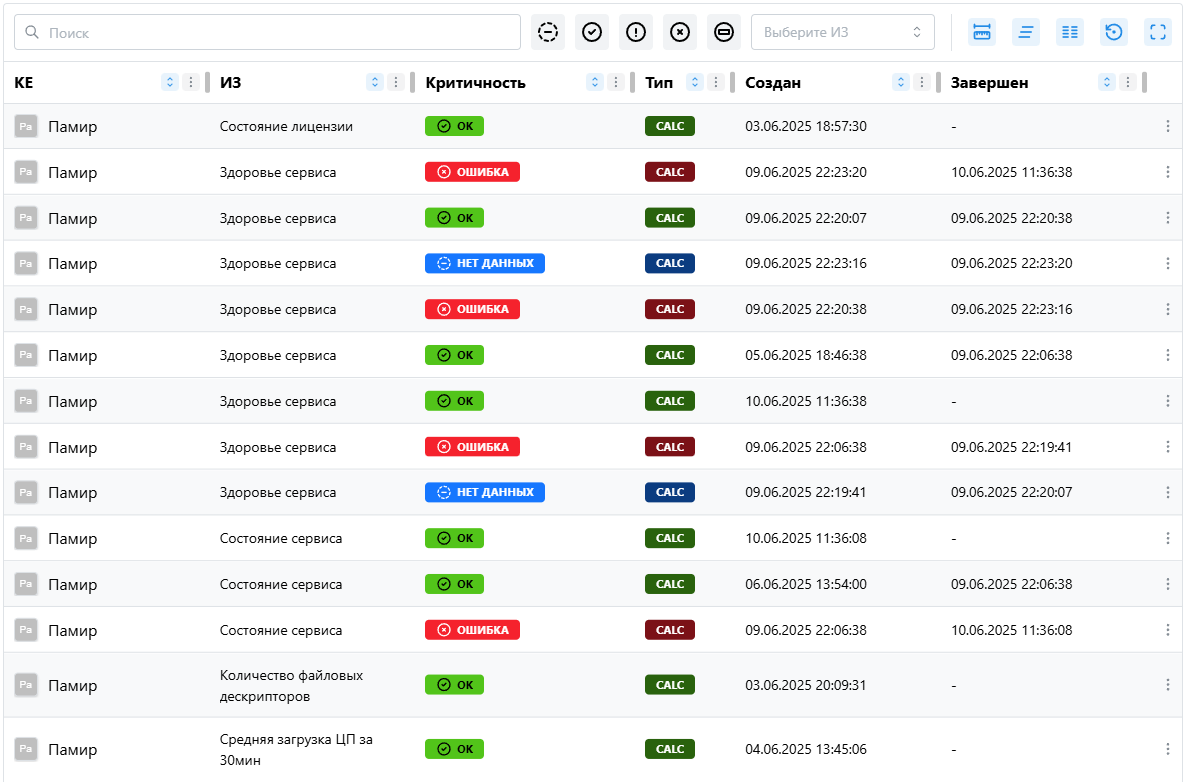
Виджет История индикаторов здоровья представляет собой табличное представление изменений состояния индикаторов здоровья (ИЗ) конфигурационных единиц (КЕ) за выбранный период времени.
Основные функции и особенности
Таблица истории индикаторов здоровья
- Отображает записи о всех изменениях ИЗ в виде сортируемой таблицы.
- Включает как активные, так и завершённые события.
- Поддерживает фильтрацию, сортировку и настройку отображаемых колонок.
Фильтрация данных
Над таблицей расположен блок фильтров, позволяющий:
- Искать события по названию КЕ.
- Фильтровать по критичности (OK, Warning, Error, Critical, No Data).
- Отбирать события по типу индикатора здоровья.
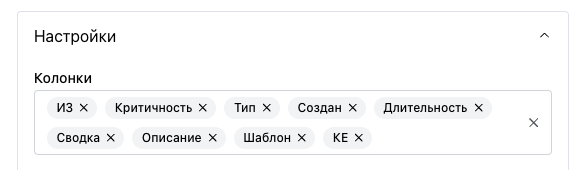
Настраиваемые колонки
Пользователь может выбрать, какие данные отображать в таблице. Доступные колонки:
- Название КЕ – имя конфигурационной единицы.
- Индикатор здоровья (ИЗ) – тип и название метрики.
- Критичность – текущий уровень серьезности (цветовая индикация).
- Тип – категория индикатора.
- Создан – время возникновения события.
- Завершён – время нормализации состояния (если применимо).
Фильтр критичности
По умолчанию доступны следующие уровни:
- Нет данных (No Data)
- OK (Норма)
- Предупреждение (Warning)
- Ошибка (Error)
- Критическая ошибка (Critical)

Сортировка данных
- Поддерживается сортировка по любой колонке (например, по времени создания или критичности).
- Можно задать направление сортировки (по возрастанию/убыванию).
Источник данных
Данные берутся из тех же источников, что и в виджете Индикаторы здоровья:
- Индикаторы здоровья, привязанные к КЕ.
- TQL-запрос, определяющий область видимости.
Одно значение
Виджет Одно значение предназначен для отображения в строковом виде значения метрики или атрибута конфигурационной единицы (например, сервера, устройства, приложения или другого объекта мониторинга).

Основные функции
- Отображение текущего значения – показывает актуальное состояние метрики (например, загрузка CPU, свободная память, статус устройства).
- Вывод атрибутов конфигурации – может отображать статические параметры объекта (версию ПО, серийный номер, IP-адрес и т. д.).
- Простота восприятия – данные выводятся в виде строки (текст или число), что удобно для быстрой проверки состояния системы.
- Интеграция в дашборды – часто используется в панелях мониторинга вместе с другими виджетами (графиками, таблицами, индикаторами).
Примеры использования
- CPU Usage:
75% - Статус сервера:
Online - Свободная память:
4.2 GB - Версия ПО:
v2.1.0
Источник данных
Виджет использует источник данных типа:
- метрики
- Значения атрибутов
- Статическое значение
Статические данные:
- массив объектов (метрик)
- каждый объект включает:
- название величины
legend - значение величины
value
- название величины
Пример:
[
{
"legend": "Метрика #1",
"value": 123
},
{
"legend": "Метрика #2",
"value": 456
}
]
В рамках одного виджета каждая метрика из массива визуально отображается отдельно.
Настройка
Для настройки виджета доступно:
- Привязка значений
- Привязка единиц измерения
- Пороговые значения
Линейный график
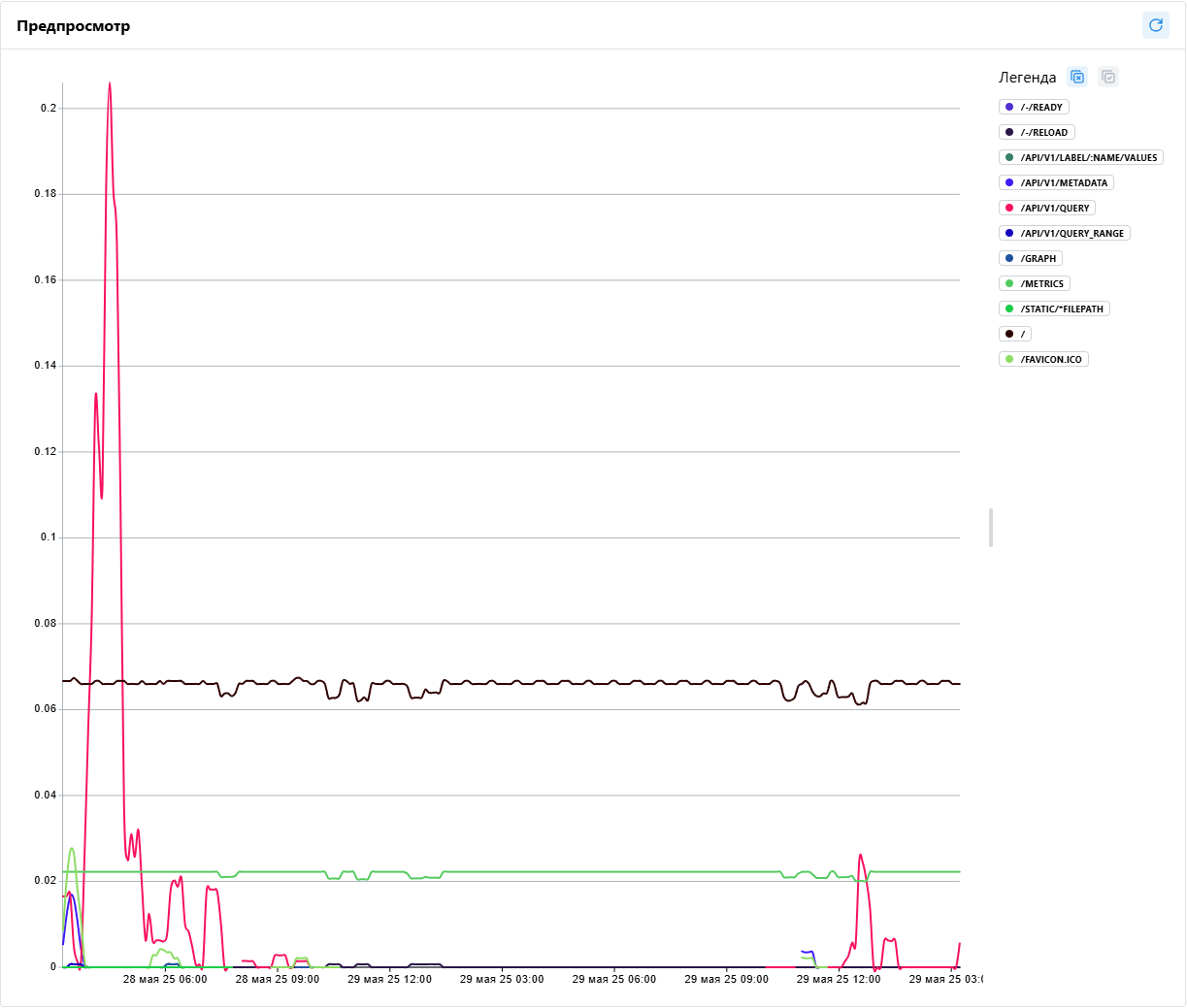
Линейный график (line chart) — это тип графика, который отображает информацию в виде серии точек, соединённых прямыми линиями. Он помогает:
- Отображать динамику: рост, падение, стабильность
- Наглядно демонстрирует эволюцию показателей (например, утилизацию ЦП)
- Позволяет сравнивать множество трендов одновременно
Источник данных
Сводная таблица использует источник данных типа метрики.
Настройка
Ось X
Позволяет выбрать единицы измерения для временной шкалы. Доступные единицы измерения ограничены временной шкалой.
Ось Y
Позволяет выбрать единицы измерения для значений графика.
Тип линии
С помощью настройки типа линий можно контролировать форму кривых для линий и областей. Доступные типы кривых:
- Линейная интерполяция
- По умолчанию для большинства серий
- Соединяет точки прямыми линиями
- Хорошо подходит для дискретных данных
- Сглаженный сплайн
- Плавные кривые без резких перегибов
- Идеально для streamgraph и плавных визуализаций
- Ступенчатая
- Горизонтальные линии с резкими вертикальными переходами
- Полезно для дискретных изменений (например, цены акций)
- Шаг до
- Изменение значения происходит перед переходом к следующей точке
- Шаг после
- Изменение значения происходит после перехода к следующей точке
Диаграмма областей
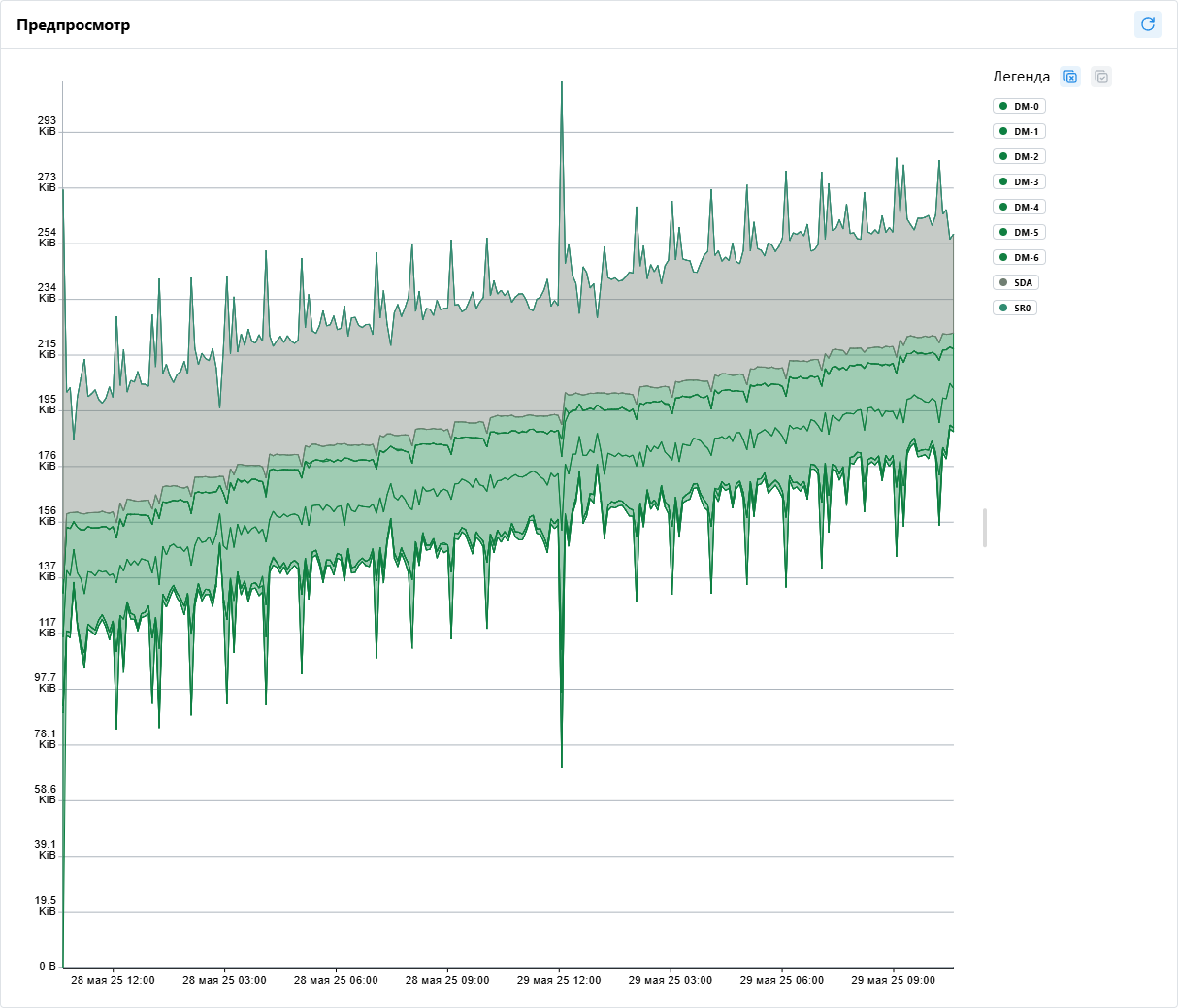
Диаграмма областей (Area Chart) — это тип графика, который отображает изменение величин во времени, визуально выделяя площадь под линией. Она помогает:
- Показывать тренды — наглядно демонстрирует рост или падение метрик.
- Сравнивать вклад категорий — если диаграмма stacked (с накоплением), можно увидеть долю каждой категории в общем объеме.
- Выявлять аномалии — резкие изменения в заполненных областях легче заметить, чем на линейном графике.
Источник данных
Сводная таблица использует источник данных типа метрики.
Настройка
Ось X
Позволяет выбрать единицы измерения для временной шкалы. Доступные единицы измерения ограничены временной шкалой.
Ось Y
Позволяет выбрать единицы измерения для значений графика.
Варианты стекирования
Настройка может принимать следующие значения:
- Нет
- Графики могут накладываться друг на друга.
- Базовая линия начинается с нуля.
- Сложение
- Графики складываются друг с другом.
- Базовая линия начинается с нуля.
- Расходящийся
- Стеки центрируются относительно нуля.
- Полезно для отображения разницы между положительными и отрицательными значениями.
- Нормализация
- Каждый стек нормализуется до 100%.
- Показывает относительные пропорции.
- Покачивание
- Минимизирует изменение наклона.
- Используется в streamgraph (визуализация потоков).
Тип линии
С помощью настройки типа линий можно контролировать форму кривых для линий и областей. Доступные типы кривых:
- Линейная интерполяция
- По умолчанию для большинства серий
- Соединяет точки прямыми линиями
- Хорошо подходит для дискретных данных
- Сглаженный сплайн
- Плавные кривые без резких перегибов
- Идеально для streamgraph и плавных визуализаций
- Ступенчатая
- Горизонтальные линии с резкими вертикальными переходами
- Полезно для дискретных изменений
- Шаг до
- Изменение значения происходит перед переходом к следующей точке
- Шаг после
- Изменение значения происходит после перехода к следующей точке
Круговая диаграмма

Круговая диаграмма (Pie Chart) — это тип графика, который используются для наглядного представления состава целого и демонстрации долевого распределения. Она помогает:
- Показывать пропорций
- Визуализация частей относительно целого
- Удобны, когда важно подчеркнуть значимость одной доли
- Сравнение ограниченного числа категорий (оптимально 2-5 сегментов)
- Демонстрация простых соотношений
- Например: 75% пользователей vs. 25% не пользователей
- Распределение типов устройств
Источник данных
Сводная таблица использует два источника данных:
- метрики
- значения атрибутов
Принцип построения для истопника данных значение атрибутов:
- Диаграмма автоматически формируется на основе выбранных атрибутов данных
- Доступен выбор одного или нескольких атрибутов для анализа
Особенности группировки данных:
-
При совпадении значений разных атрибутов система объединяет их в единый сегмент диаграммы
-
Каждый сегмент визуализирует суммарное значение всех совпадающих элементов
Настройка
Настройки круговой диаграммы позволяют выполнять:
- Привязку значений
- включать аннотации
- выбирать режим отображения значений:
- значение
- процент
- процент и значение
Шкала
Виджет Шкала предназначен для наглядного отображения значения метрики в процентном соотношении. Он визуализирует данные в виде заполняющегося сосуда (например, линейного индикатора, круговой шкалы или столбчатой диаграммы), где:
- 0% соответствует пустому состоянию,
- 100% — полностью заполненному.
Формат входных данных:
- Принимает значение метрики в диапазоне от 0 до 1 (где 0 = 0%, 0.5 = 50%, 1 = 100%).
- Поддерживает динамическое обновление данных.

Источник данных
Виджет использует источник данных:
Настройка
Настройки виджета позволяют выполнять:
Примеры использования
- Отображение уровня заряда батареи.
- Загрузка системы (CPU, RAM, диск).
Таблица КЕ
Таблица КЕ предоставляет возможность отображать атрибуты конфигурационных единиц (КЕ) в виде таблицы. Поддерживаются следующие функции:
- Сортировка — данные можно упорядочивать по значениям атрибутов.
- Поиск — доступен поиск по исходным значениям атрибутов.
Режимы отображения:
-
Вся область видимости TQL
- Все КЕ отображаются в одной таблице, независимо от их типа.
-
Узлы TQL
- Для каждого узла TQL создается отдельная вкладка.
- На вкладке отображаются только КЕ, соответствующие выбранному узлу.
Это позволяет гибко настраивать представление данных в зависимости от задач пользователя.
При отрисовке значение схема атрибута не учитывается. Значение атрибутов выводятся в виде строки. Для замены значений нужно использовать пункт Привязка значений из настройки виджета.
Источник данных
Таблица КЕ использует источник данных типа Значения атрибутов.
Настройка
Настройки таблицы КЕ позволяют выполнять:
- Привязку значений
- Привязку единиц измерения
- Сортировку таблицы по умолчанию
- Привязку пороговых значений
Каждая настройка применяется к выбранному перечню столбцов. Столбцы строятся на базе атрибутов CMDB.
Сводная таблица
Сводная таблица — это инструмент для агрегации и структурирования данных, который позволяет:
- Группировать данные по одному или нескольким полям (строкам и столбцам).
- Агрегировать значения (сумма, среднее, количество и др.) на пересечении групп.
- Анализировать данные в компактном и наглядном формате, выявляя закономерности.
Ключевые компоненты сводной таблицы
- Строки (rows) — категории для группировки (например, даты, регионы, продукты).
- Столбцы (columns) — дополнительные уровни детализации (например, статусы, типы).
- Значения (values) — числовые данные, к которым применяются агрегационные функции (
SUM,AVG,COUNTи др.).
Строки и столбцы формируются из значений выбранных меток (например, instance, pod, service).
Пример сводной таблицы использования CPU и памяти серверов, сгруппированных по окружениям (env) и ролям (role)
Исходные метрики в Prometheus:
node_cpu_usage_seconds_total(метки:instance,env=prod|dev|stage,role=web|db|cache)node_memory_usage_bytes(метки:instance,env,role)
| Окружение \ Роль | Web (CPU %) | DB (CPU %) | Cache (CPU %) | Web (RAM GB) | DB (RAM GB) | Cache (RAM GB) |
|---|---|---|---|---|---|---|
| Prod | 45% | 78% | 32% | 12.4 | 24.7 | 5.2 |
| Stage | 32% | 65% | 28% | 8.1 | 18.3 | 4.0 |
| Dev | 15% | 40% | 10% | 4.5 | 9.8 | 2.1 |
Как это построено:
- Строки: Окружения (env).
- Столбцы:
- Группировка по ролям (role).
- Подстолбцы для CPU и RAM.
- Значения:
- CPU:
avg(rate(node_cpu_usage_seconds_total[1h])) by (env, role)→ преобразовано в %. - RAM:
avg(node_memory_usage_bytes / 1024^3) by (env, role)→ в гигабайтах.
- CPU:
Источник данных
Сводная таблица использует источник данных типа метрики.
Настройка
Название таблицы - заполняет ячейку в левом верхнем углу. По умолчанию название берется из агрегатной функции.
Функция агрегации - применяет выбранную функцию (count, sum, avg) к значениям метрик.
Столбцы и Строки - заполняются названием меток метрики. Порядок меток определяет порядок группировки сводной таблицы. Имена меток задаются пользователем самостоятельно.
Для примера создадим таблицу с настройками:
- значения столбцов
name,code - значением строк
job,handler - функцией агрегации
sum(Сумма элементов)
Источниками данных являются метрики:
prometheus_http_requests_totalprometheus_http_request_duration_seconds_sum
В заголовках строк и столбцов будет несколько уровней. Ячейка на пересечении
строки services и столбцов prometheus_http_requests_total,200 - суммирует информацию по всем метрикам, чьи метки
удовлетворяют условиям job = services, __name__ = prometheus_http_requests_total, code = 200
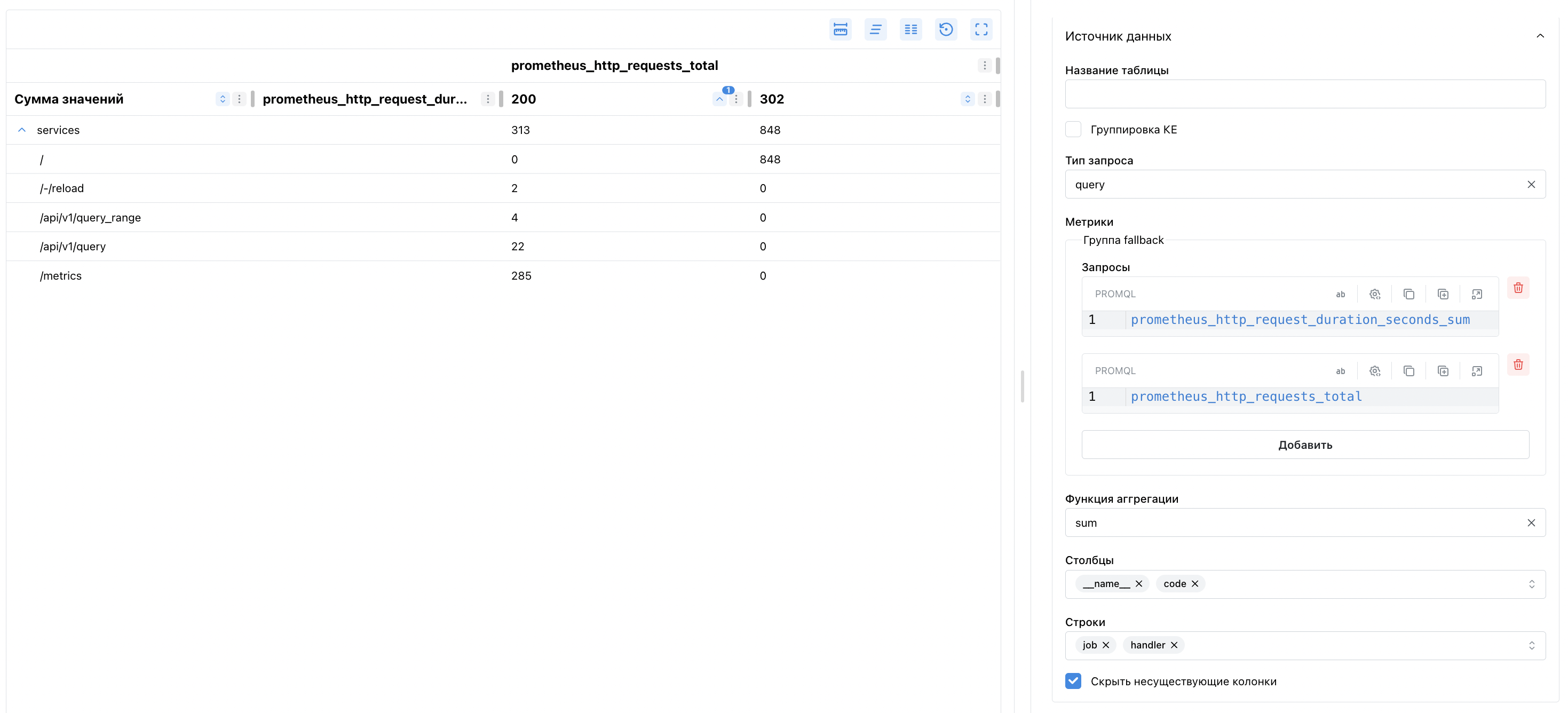
Строка services содержит промежуточный итог по всем вложенным подстрокам:
//-/reload/api/v1/query- т.д.
Возможны ситуации при которых у столбца __name__ с конкретным названием (например, prometheus_http_request_duration_seconds_sum),
не существует меток code, как у других меток. В таком случае уровень столбцов для code
в prometheus_http_request_duration_seconds_sum будет пустым. Значения в ячейках пересечения будет тоже пустыми.
Виджет скрывает такие ячейки. Для отображения пустых ячеек нужно отключить параметр "Cкрыть несуществующие колонки".
Единицы измерения
Для привязки единиц измерения к метрике необходимо в поле Название метрики указать сырое название метрики.
Привязка единиц измерения не выполняется, если к одной метрике привязано более одной единицы измерения.
Начальная сортировка
Для настройки сортировки нужно указать список столбцов по которым будет выполняться сортировка. Список столбцов указывается в формате:
- название колонки
- направление сортировки
В название колонки добавлять нужно только названия нижних столбцов, которые имеют значок сортировки.
Порядок столбцов в настройке сортировки определяет порядок сортировки в сводной таблице.
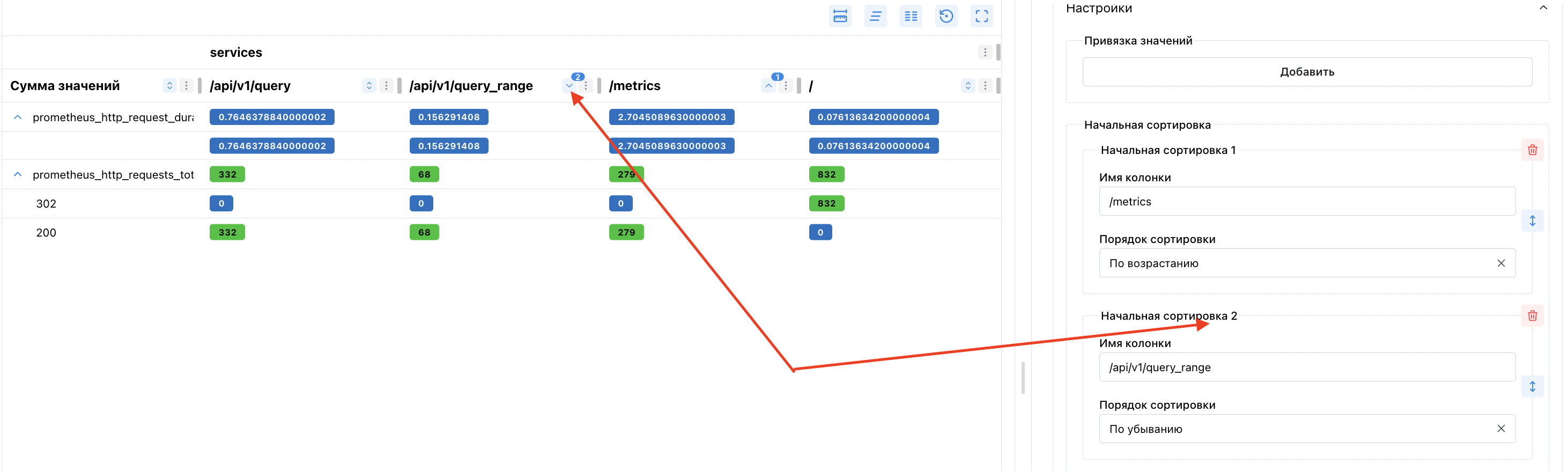 Порядок сортировки строк
Порядок сортировки строк
Пороговые значения
Примение пороговых значений работают по принципу выбора названия столбца и строки, после чего на пересечение данных (также субстрок и субстолбцов) названий к значению в ячейке будут применяться парвило расчета порогового значения.
При выборе только столбца либо строки в мультиселекте, будет окрашиваться весь столбец/строчка, а также субстроки и субстолбцы.
Для варианта с пустыми и столбцом, и строкой, окрашивается вся таблица.
При накладывании на одну и ту же ячейку нескольких правил пороговых значений, последующие правила будут перезаписывать предыдущие.
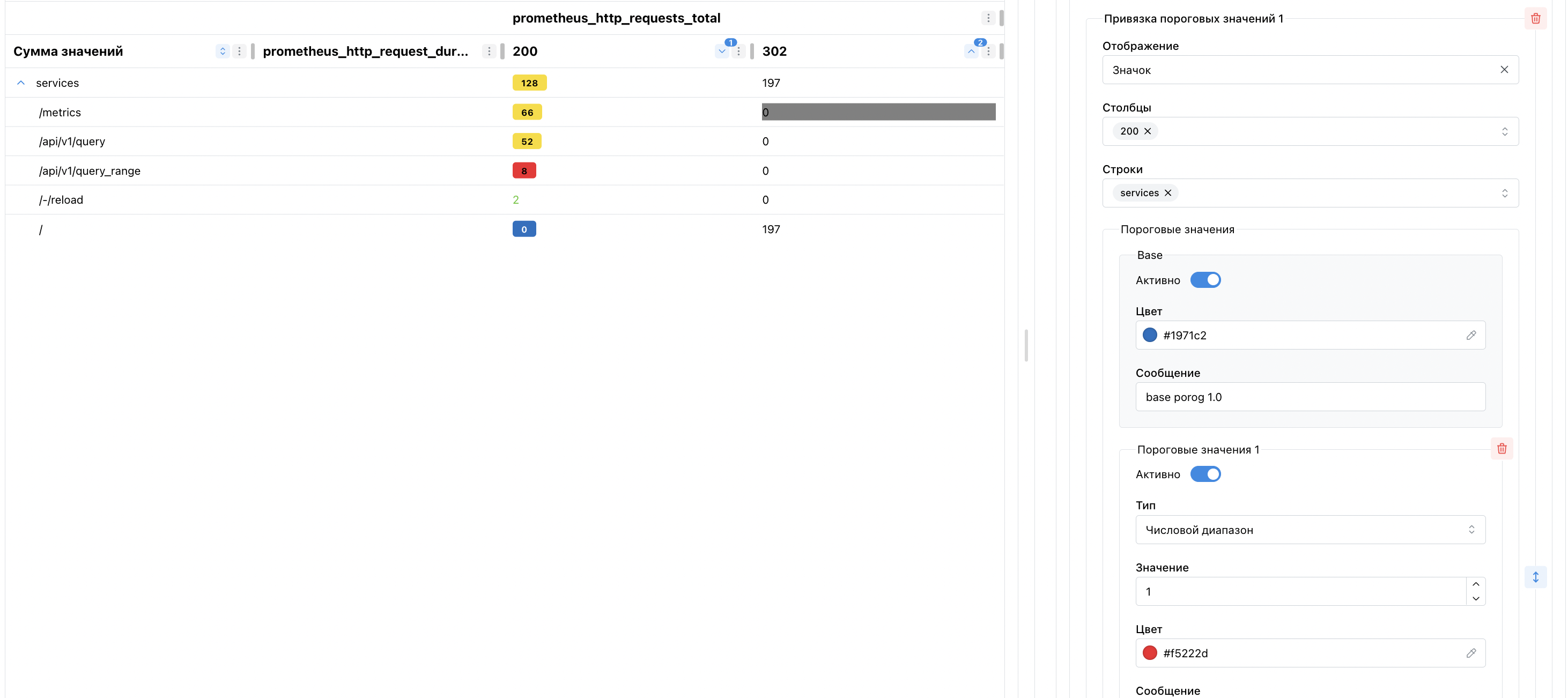 Примененные пороговые значения
Примененные пороговые значения
История индикаторов здоровья
Виджет История индикаторов здоровья отвечает за отображение истории индикаторов здоровья КЕ на временной шкале.

Измерение
Виджет Измерение - это визуальный элемент интерфейса, который отображает насколько текущий показатель близок к минимуму, норме или максимуму.
- Отображает значение (например, скорость, уровень загрузки, эффективность) в виде стрелки, перемещающейся по шкале.
- Позволяет быстро оценить, насколько текущий показатель близок к минимуму, норме или максимуму.

Источник данных
Виджет использует источник данных типа метрики. Конфигурация источника данных содержит два поля запроса:
- Возвращает текущее значение
- Возвращает максимальное значение
Алгоритм работы в случае нескольких значений метрики
Виджет отображает один или несколько индикаторов (спидометров/прогресс-баров) на основе данных из двух запросов:
- Запрос 1 — текущие значения (может содержать одно или несколько значений).
- Запрос 2 — максимальные значения (может содержать одно или несколько значений).
Количество отображаемых виджетов и их параметры определяются по следующему алгоритму.
| Сценарий | Количество виджетов | Максимальное значение для каждого виджета |
|---|---|---|
| 1-й запрос: 1 значение 2-й запрос: 1 значение | 1 | Используется единственное значение из 2-го запроса. |
| 1-й запрос: N значений 2-й запрос: 1 значение | N | Для всех виджетов используется одно значение из 2-го запроса. |
| 1-й запрос: N значений 2-й запрос: M значений (N ≤ M) | N | Для i-го виджета берётся i-е значение из 2-го запроса (если есть). Если i > M — берётся последнее значение из 2-го запроса. |
| 1-й запрос: N значений 2-й запрос: M значений (N > M) | N | Для i-го виджета берётся i-е значение из 2-го запроса (если i ≤ M). Если i > M — берётся последнее значение из 2-го запроса. |
Примеры
Пример 1:
currentValues = [50, 70, 30](3 значения)maxValues = [100](1 значение)
Результат:- 3 виджета, у каждого
max = 100.
Пример 2:
currentValues = [10, 20, 30](3 значения)maxValues = [50, 60](2 значения)
Результат:- 3 виджета:
- Виджет 1:
current=10,max=50(maxValues[0]) - Виджет 2:
current=20,max=60(maxValues[1]) - Виджет 3:
current=30,max=60(последнее значение maxValues)
- Виджет 1:
Пример 3:
currentValues = [15](1 значение)maxValues = [30, 40, 50](3 значения)
Результат:- 1 виджет:
current=15,max=30(maxValues[0]).
Настройка
Для настройки виджета доступно:
- Настройка пороговых значений
- Настройка единиц измерения
Карта
Виджет Карта позволяет отображать расположение КЕ на географических координатах и состояния их ИЗ. Значения координат и состояний КЕ могут обновляться в фоновом режиме.

Вложенный дашборд
Вложенный дашборд представляют собой виджет дашборда с параметризированным TQL запросом.
 Виджет вложенного дашборда состоит из 2-ух частей:
Виджет вложенного дашборда состоит из 2-ух частей:
- Слева - Дерево КЕ основанное на TQL родительского дашборда
- Справа - Представление дашборда привязанного к элементам дерева слева
Для работы виджета в настройках необходимо настроить иерархию дерева TQL. Для этого выбираем из доступных узлов TQL выбираем нужные нам для построения дерева, после чего выстраиваем их иерархию.

После этого необходимо добавить группы привязки и связать элементы дерева с узлами TQL:
-
Для КЕ (листьев дерева) - сохраненный дашборд и узел TQL этого дашборда

-
Для группы КЕ (ветвь дерева) - сохраненный дашборд и узел TQL этого дашборда
