Индикаторы здоровья
Индикатор здоровья (Health Indicator) — это показатель, который используется для оценки состояния системы, приложения, сервиса или инфраструктуры. Он помогает определить, насколько хорошо работает система, и выявить потенциальные проблемы.
Основные характеристики индикаторов здоровья:
- Простота: Индикатор должен быть легко интерпретируемым.
- Релевантность: Он должен отражать ключевые аспекты работы системы.
- Достоверность: Индикатор должен точно отражать состояние системы.
- Оперативность: Данные должны обновляться в реальном времени или с минимальной задержкой.
Примеры индикаторов здоровья
1. Для веб-приложений:
- Доступность (Availability): Процент времени, когда приложение доступно для пользователей.
- Время ответа (Response Time): Среднее время, за которое приложение обрабатывает запросы.
- Частота ошибок (Error Rate): Количество ошибок (например, 5xx) на общее количество запросов.
- Загрузка CPU и памяти: Использование ресурсов сервера.
2. Для баз данных:
- Количество активных подключений: Число текущих подключений к базе данных.
- Задержка запросов (Query Latency): Время выполнения запросов.
- Размер базы данных: Использование дискового пространства.
3. Для микросервисов:
- Healthcheck: Результат проверки работоспособности сервиса (например, HTTP-запрос на
/health). - Пропускная способность (Throughput): Количество обработанных запросов в единицу времени.
- Задержка (Latency): Время обработки запросов.
4. Для инфраструктуры:
- Состояние серверов: Работают ли серверы (например, ping или статус в мониторинговой системе).
- Использование сети: Количество входящего и исходящего трафика.
- Свободное место на диске: Достаточно ли места для хранения данных.
Как используются индикаторы здоровья?
- Мониторинг - визуализация индикаторов здоровья на дашбордах и в CMDB.
- Оповещения - отправка уведомлений в Telegram или по E-mail.
Реестр индикаторов здоровья
Реестр индикаторов здоровья находится на странице Главная / Настройки / Мониторинг / Индикаторы здоровья.
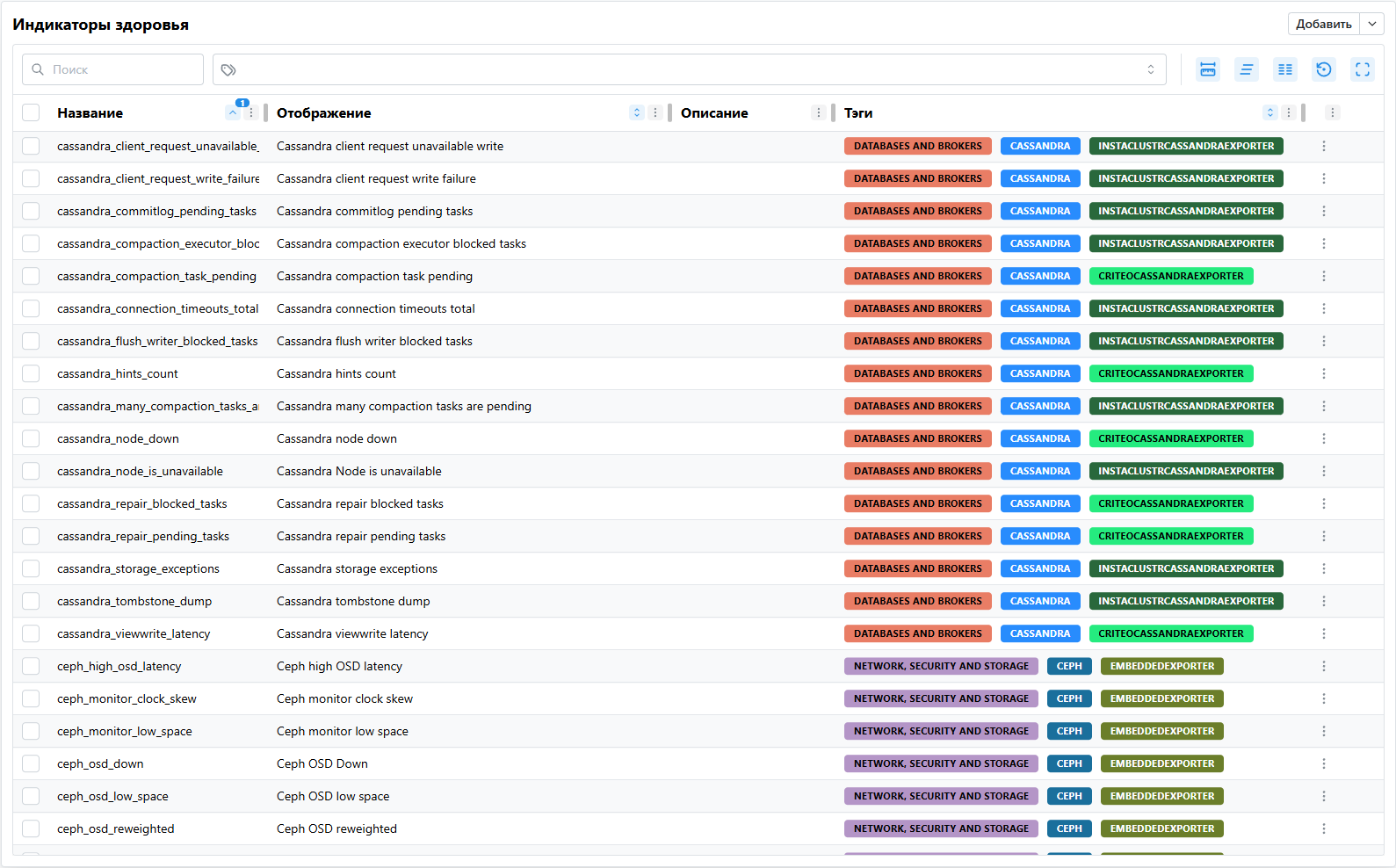
Реестр содержит индикаторы здоровья, которые могут быть привязаны к конкретным КЕ по средствам шаблонов мониторинга. Индикатор здоровья помимо описательной части (название, отображение, описание), может содержать правило генерации тревоги, на основе метрик, собранных Prometheus.
Структура конфигурации индикатора здоровья:
- alert - название алерта
- expr - выражение на языке PromQL, которое определяет условие для срабатывания алерта
- for - время, в течение которого условие должно быть истинным, прежде чем алерт сработает.
- labels - дополнительные метки, которые добавляются к алерту (например,
severity: critical). - annotations - дополнительная информация, которая отображается в уведомлениях (например,
summaryиdescription).
Изменение конфигурации индикатора здоровья не приводят к обновлению кофнигуарциии в шаблонах мониторинга. Кофнигуарция используется в качестве шаблона при создании индикатора метрики.
При удалении индикатор будет исключен из реестра. Удаление индикатора здоровья повлечет за собой удаление всех настроенных индикаторов на объектах контроля, связанных с удаляемым типом.
Типы индикаторов здоровья
В зависимости от источника данных индикаторы здоровья бывают следующих типов:
- Индикатор метрики:
- Источник данных - метрика
- Метрика в обязательном порядке должна содержать лейбл
ci_id
- Индикатор метрики (ci_hint)
- Источник данных - метрика
- Метрика в обязательном порядке должна содержать лейбл
ci_hint
- Расчетный индикатор
- Источник данных - индикаторы здоровья любого типа
Индикатор метрики
Индикатор метрики — позволяет оценивать состояние КЕ на основе метрики.
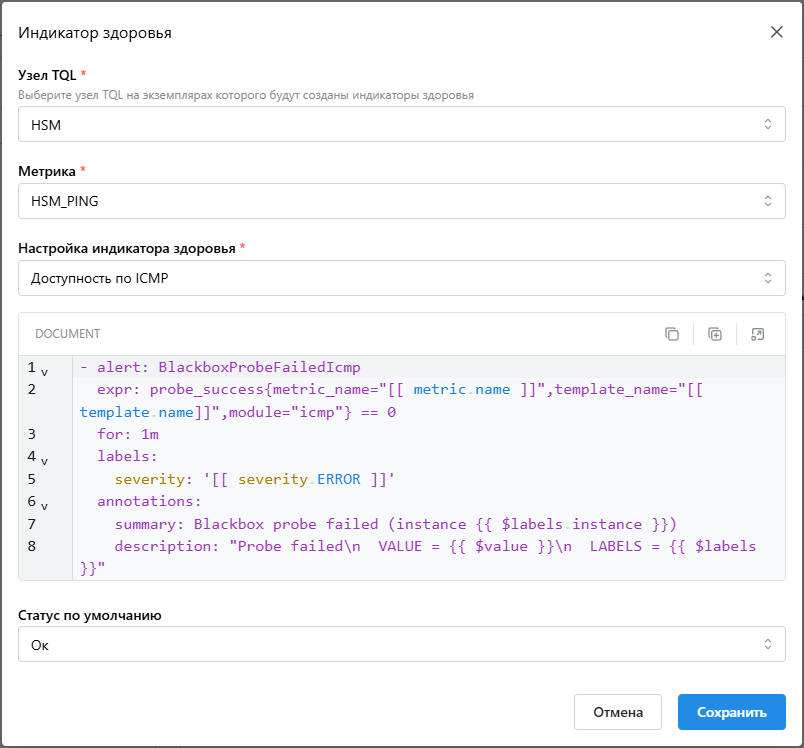
Индикатор метрики требует обязательного указания метрики, созданной в текущем шаблоне мониторинга. Метрика должна включать
лейбл ci_id. Лейбл ci_id используется для сопоставления алертов с КЕ. Если лейбл ci_id будет отсутствовать алерт не сможет
привязаться к КЕ.
При настройке ИЗ должны быть указаны:
- Узел TQL - Узел TQL к экземплярам которого будут привязаны индикаторы здоровья
- Индикатор здоровья - Название индикатора здоровья из реестра
- Метрика - Метрика, определенная в текущем шаблоне мониторинга
- Правило алертинга - Описание условия для срабатывания алерта
- Критичность по умолчанию - Уровень критичности, который приобретет индикатор здоровья в случае отсутствия алерта
Область применения
Индикаторы метрик предназначены для оценки состояния атомарных объектов — объектов мониторинга, которые не требуют декомпозиции на составные части.
Пример использования
Сетевое устройство может рассматриваться в двух вариантах:
Как единый объект
В этом случае устройство оценивается целиком, без разделения на компоненты.
- Метрики собираются для всего устройства.
ci_idсоответствует самому устройству.- Индикаторы метрик корректно отражают состояние устройства.
С декомпозицией на компоненты
Если устройство разбито на составные части (например, интерфейсы), индикаторы метрик не подходят для оценки состояния отдельных компонентов.
- Метрики могут собираться через одну точку интеграции, но привязаны к
ci_idустройства, а не его компонентов. - Индикаторы метрик не могут быть использованы для интерфейсов, так как отсутствует связь по
ci_id.
Ограничения
- Индикаторы метрик не поддерживают декомпозицию объекта мониторинга.
- Если требуется оценивать состояние подкомпонентов (например, интерфейсов, дисков, сервисов), необходимо использовать
- Индикатор метрики (ci_hint), обеспечивающие связь метрик без использования
ci_id.
Индикатор метрики (ci_hint)
Индикатор метрики — позволяет оценивать состояние КЕ на основе метрики.
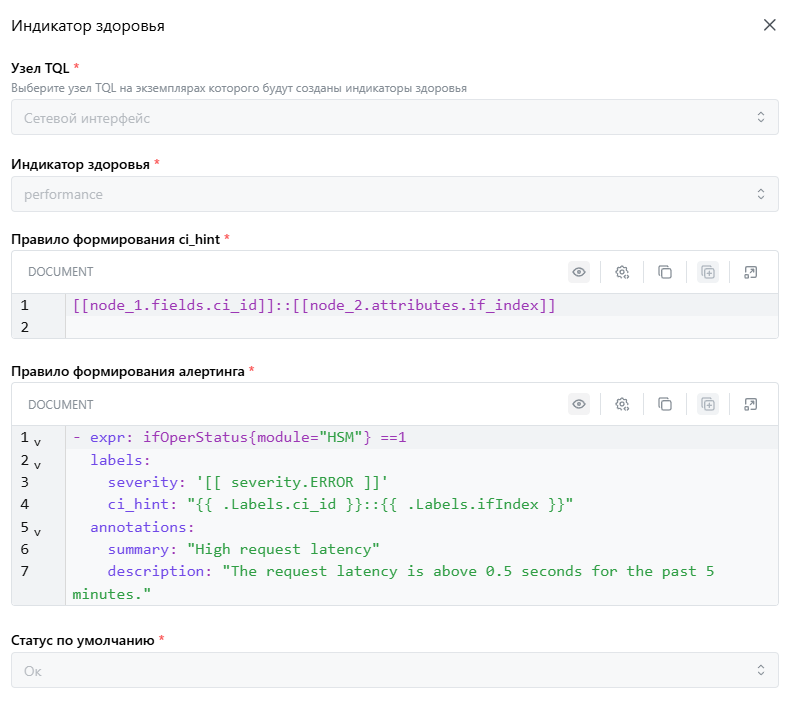
Индикатор рассчитан на привязку алертов Prometheus, которые не содержат ci_id. Для привязки алерта к КЕ
нужно ввести альтернативный параметр ci_hint, по которому будет выполняться привязка.
При настройке ИЗ должны быть указаны:
- Узел TQL - Узел TQL к экземплярам которого будут привязаны индикаторы здоровья
- Индикатор здоровья - Название индикатора здоровья из реестра
- Метрика - Метрика, определенная в текущем шаблоне мониторинга
- Правило генерации
ci_hint- правило формирования уникальной строки, идентифицирующей КЕ - Правило алертинга - Описание условия для срабатывания алерта
- Критичность по умолчанию - Уровень критичности, который приобретет индикатор здоровья в случае отсутствия алерта
Общее о ci_hint
ci_hintэто строкаci_hintсуществует на стороне алерта, представляет собой label, значение которого формируется в момент формирования события в Prometheusci_hintсуществует на стороне индикатора здоровья
Генерация ci_hint в ИЗ
В ИЗ должен быть введен шаблон формирования ci_hint. Шаблон должен описывать правила формирования
строки, оперируя знаниями о КЕ доступных в ШМ, их связанности, их атрибутах и полях. Шаблон формирования ci_hint в значительной
степени похож на шаблон формирования таргета для метрики.
Пример:
[[node_1.attributes.name]]::[[node_2.attributes.name]]
ci_hint должен обновляться по факту:
- изменения структуры СРМ
- изменения TQL ШМ
- изменения атрибутов КЕ, участвующих в разрешении шаблона
ci_hint должен записываться в отдельную колонку his_composite. Поиск КЕ для пришедшего алерта должен осуществляться
по alertname И ci_hint.
Генерация ci_hint в правиле алертинга
Пример:
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: critical
ci_hint: "{{ .Labels.job }}::{{ .Labels.instance }}"
annotations:
summary: "High request latency"
description: "The request latency is above 0.5 seconds for the past 5 minutes."
Расчетный индикатор
Использование ссылок на КЕ в шаблонизаторе ci_hint
Общий вид ссылки:
<узел_tql>.<ключевое_слово>.<название_атрибута_или_поля>
<узел_tql> идентифицируется номером. Номер - натуральное число > 0. Для упрощения восприятия пользователем к номеру
узла добавляется название ТКЕ. Итоговый вид узла TQL: <название_ТКЕ>_<номер_ноды_в_tql>. <узел_tql> может быть не
указано.
<ключевое_слово> - строковый литерал, принимающий одно из значений (перечень значений может быть расширен):
attributes: используется для адресации к атрибутам ТКЕfields: используется для адресации к системным полям ТКЕ
<название_атрибута_или_поля> - название атрибута ТКЕ или системного поля ТКЕ. Перечень названий атрибутов - не ограничен,
определяется исходя из привязанных к ТКЕ атрибутов.
Перечень системных полей:
ci_idci_nameci_type_name