Метрики
Метрики – это количественные показатели, характеризующие состояние и производительность системы, приложения или инфраструктурного компонента. Они представляют собой числовые данные, собранные за определённый промежуток времени.
Примеры метрик:
- Загрузка CPU (
cpu_usage); - Объем свободной памяти (
free_memory_bytes); - Количество HTTP-запросов в секунду (
http_requests_total); - Латентность базы данных (
db_query_duration_seconds).
Основные цели использования метрик:
- Оценка состояния системы – позволяют понять, работает ли компонент в штатном режиме.
- Выявление аномалий – резкие изменения метрик (например, скачок CPU) могут указывать на проблемы.
- Анализ производительности – помогают находить узкие места и оптимизировать систему.
- Прогнозирование – на основе исторических данных можно предсказывать нагрузку (например, автоскейлинг).
- Автоматизация реакций – используются в алертинге для триггеров оповещений (например, при достижении порога
disk_usage > 90%).
Метрики – это временные ряды (time series), то есть последовательность значений, каждое из которых имеет метку времени.
http_requests_total{method="GET", endpoint="/api"} 1500 @1700000000
http_requests_total{method="GET", endpoint="/api"} 1520 @1700000060
Здесь:
http_requests_total– имя метрики;{method="GET", endpoint="/api"}– лейблы (доп. атрибуты);1500,1520– значения;@1700000000,@1700000060– временные отметки (Unix timestamp).
Основные характеристики метрик
-
Имя метрики:
- Уникальное имя, которое описывает, что измеряется (например,
http_requests_total,cpu_usage).
- Уникальное имя, которое описывает, что измеряется (например,
-
Метки (labels):
- Пары ключ-значение, которые добавляют контекст к метрике (например,
method="GET",status="200",instance="localhost:9090"). - Метки позволяют фильтровать, группировать и агрегировать данные.
- Пары ключ-значение, которые добавляют контекст к метрике (например,
-
Значение метрики:
- Числовое значение, которое может быть целым или вещественным числом (например, количество запросов, время ответа, использование памяти).
-
Тип метрики:
- Типы метрик:
- Counter: монотонно возрастающее значение (например, общее количество запросов).
- Gauge: значение, которое может увеличиваться или уменьшаться (например, температура, использование памяти).
- Histogram: распределение значений по корзинам (buckets) (например, время ответа).
- Summary: аналогично гистограмме, но с предварительно вычисленными квантилями.
- Типы метрик:
-
Временные метки (timestamps):
- Каждая метрика связана с временной меткой, которая указывает, когда было измерено значение.
Сбор метрик
Для сбора метрик Памир использует стек технологий Prometheus. В состав Памир включены:
- экземпляр Prometheus
- экспортеры:
- blackbox
- snmp
- sql
- postgres
- node
- docker-state
- cadvisor
- json
Управление конфигурацией Prometheus осуществляется через страницу Главная/Настройки/Мониторинг/Prometheus/Конфигурация.
Конфигурация со страницы используется напрямую в Prometheus.
Особенности работы с конфигуарцией Prometheus:
- scrape_configs
- управляется Памир
- изменения, сделанные в этом более конфигурации вручную не будут приняты Prometheus
- настройку заданий (jobs) необходимо выполнять в пункте меню
Главная/Настройки/Мониторинг/Задания
- rule_files
- управляется Памир
- изменения, сделанные в этом более конфигурации вручную не будут приняты Prometheus
- настройку правил алертинга необходимо выполнять через шаблоны мониторинга
Задания
Задания (Jobs) определяют, какие метрики, откуда и как собирать. Они являются основным механизмом настройки сбора данных и позволяют гибко конфигурировать мониторинг различных сервисов, экспортеров и приложений.
Задания выполняют несколько ключевых функций:
-
Определяют цели (targets) для сбора метрик
- Указывают, с каких хостов/сервисов Prometheus должен собирать данные.
- Например: мониторинг Node Exporter, веб-серверов, баз данных и т. д.
-
Задают параметры сбора
- Как часто опрашивать (
scrape_interval). - По какому пути запрашивать метрики (
metrics_path). - Использовать ли HTTPS или HTTP (
scheme).
- Как часто опрашивать (
-
Управляют метками (labels)
- Добавляют или изменяют метки для целей (например,
env=prod,team=devops). - Позволяют фильтровать и группировать данные в Grafana и Alertmanager.
- Добавляют или изменяют метки для целей (например,
-
Поддерживают Service Discovery
- Автоматически находят новые цели в Kubernetes, Consul, AWS и других системах.
Конфигурация задания
Конфигурирование задания выполняется на странице Главная/Настройки/Мониторинг/Задания.
- Имя - название задания
- Шаблон - конфигурация задания
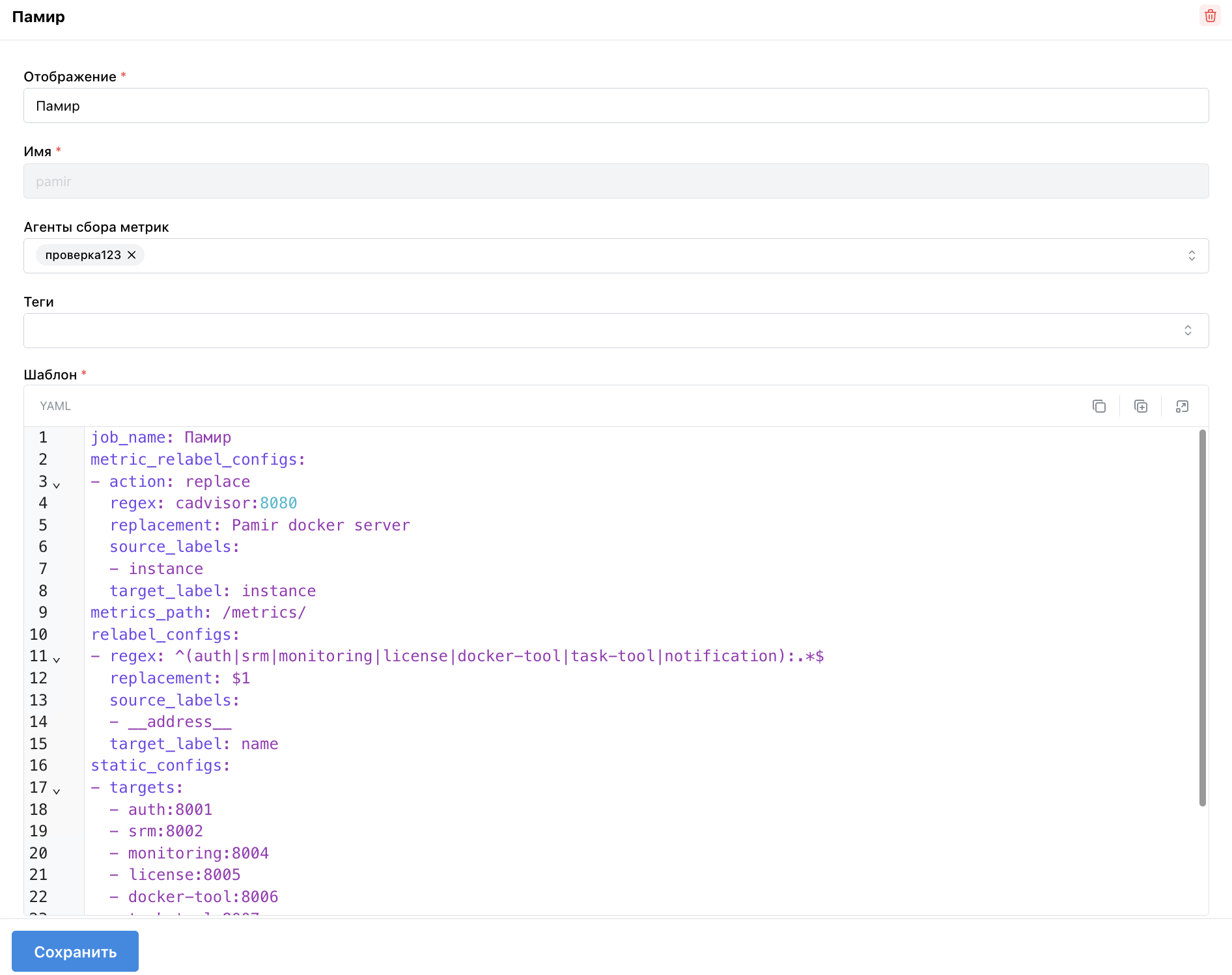
Пример конфигурации:
job_name: Памир # Название задания можно не указывать к конфигурации
metrics_path: /metrics
static_configs:
- targets:
- auth:8001
- srm:8002
- monitoring:8004
- license:8005
- docker-tool:8006
- task-tool:8007
- notification:8008
- cadvisor:8080
- docker-state-exporter:8080
relabel_configs:
- source_labels:
- __address__
regex: ^(auth|srm|monitoring|license|docker-tool|task-tool|notification):.*$
target_label: name
replacement: $1
metric_relabel_configs:
- source_labels:
- instance
regex: cadvisor:8080
target_label: instance
replacement: Pamir docker server
action: replace
Основные параметры задания
| Параметр | Описание | Пример |
|---|---|---|
job_name | Уникальное имя задания | 'node-exporter' |
scrape_interval | Частота сбора метрик | 15s, 1m |
metrics_path | Путь к эндпоинту метрик | '/metrics' (по умолчанию) |
scheme | Протокол (http/https) | 'https' |
static_configs | Список целей вручную | targets: ['host:port'] |
relabel_configs | Переименование/фильтрация меток | См. выше |
params | GET-параметры запроса | {'module': ['http_2xx']} |
sample_limit | Макс. число метрик с одной цели | 5000 |
Динамическое создание таргетов
Памир предоставляет возможность динамического создания таргетов для заданий на основе данных из CMDB (Configuration Management Database). Эта функциональность позволяет автоматически генерировать и поддерживать в актуальном состоянии цели мониторинга, что особенно полезно в крупных и динамически изменяющихся ИТ-инфраструктурах.
Основные понятия
- Таргет - объект мониторинга или управления, который может представлять собой устройство, сервис, приложение или другой компонент инфраструктуры.
- CMDB - база данных управления конфигурациями, содержащая информацию о конфигурационных единицах (КЕ) и их взаимосвязях.
- TQL - язык запросов для определения области действия шаблонов мониторинга.
- Jinja2 - современный шаблонизатор для Python, используемый для генерации таргетов.
Процесс создания динамических таргетов
1. Создание шаблона мониторинга
Шаблон мониторинга определяет:
- Область действия
- Параметры сбора метрик
- Параметры индикаторов здоровья, включая пороги срабатывания предупреждений
2. Определение области действия с помощью TQL
TQL запрос определяет, к каким конфигурационным единицам (КЕ) из CMDB будет применяться шаблон мониторинга. Пример TQL запроса:
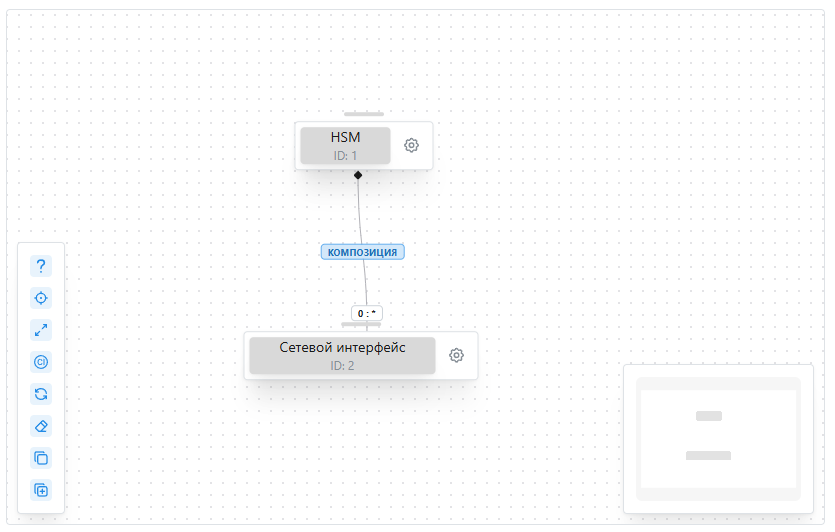
3. Создание метрики, привязанной к узлу TQL
Для каждого узла, возвращаемого TQL запросом, создается соответствующая метрика:
- Может быть дополнительно настроена с учетом атрибутов конкретной КЕ
4. Шаблон формирования таргета
Шаблон таргета реализован с использованием шаблонизатора Jinja2 и поддерживает следующие возможности:
- Использование атрибутов и полей КЕ
- Условные операторы
- Циклы
- Работа со связанными КЕ
5. Поддержка таргетов в актуальном состоянии
Памир автоматически отслеживает изменения в CMDB и соответствующим образом обновляет таргеты:
Отслеживаемые изменения:
- Создание/удаление КЕ: при добавлении новой КЕ, соответствующей TQL запросу, автоматически создается новый таргет; при удалении - таргет удаляется.
- Создание/удаление связи: изменение связей между КЕ может привести к изменению сгенерированных таргетов.
- Изменение значения атрибута: если измененный атрибут используется в TQL запросе или шаблоне таргета, таргет будет соответствующим образом обновлен.
Механизм обновления:
- Памир подписывается на события изменения CMDB
- При обнаружении релевантного изменения система пересчитывает TQL запрос
- Для измененных узлов перегенерируются таргеты
- Обеспечивается атомарность изменений - все связанные таргеты обновляются согласованно
Рекомендации по использованию
- Оптимизация TQL запросов: избегайте слишком широких запросов, которые могут привести к созданию избыточных таргетов.
- Обработка ошибок в шаблонах: предусматривайте значения по умолчанию для потенциально отсутствующих атрибутов.
- Тестирование шаблонов: перед применением в production проверяйте шаблоны на тестовых данных.
- Мониторинг процесса генерации: отслеживайте количество создаваемых таргетов и их изменения.
- Версионирование шаблонов: сохраняйте историю изменений шаблонов для возможности отката.
Форма создания метрики
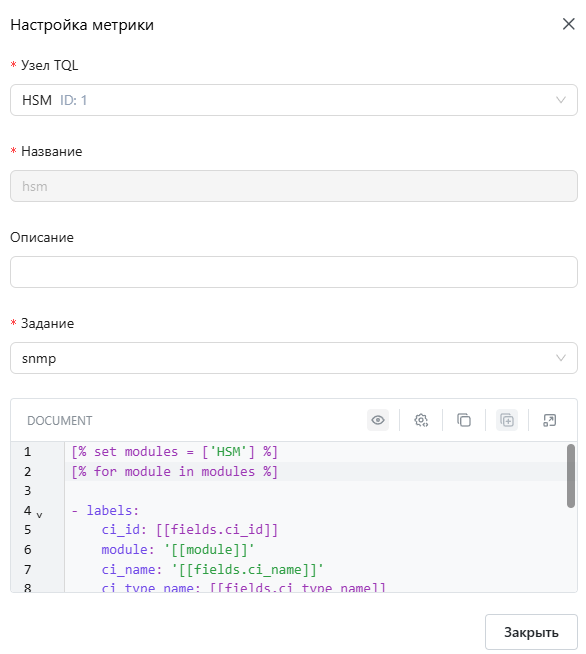
Для создания метрики на базе CMDB нудно заполнить форму:
- Узел TQL - Узел TQL к экземплярам которого будут привязаны индикаторы здоровья
- Название - Уникальное название метрики. Название должно содержать только латинские буквы, цифры или "_"
- Описание - Описание метрики
- Задание - Задание (Job) prometheus, в которое будут добавлены таргеты (targets)
- Шаблон конфигурации таргетов (targets) - Шаблон конфигурации таргетов используется для динамического создания таргетов на основе КЕ
Пример шаблона:
- labels:
ci_id: '[[fields.ci_id]]'
ci_name: '[[fields.ci_name]]'
metric_name: '[[fields.metric_name]]'
template_name: '[[fields.template_name]]'
targets:
- '[[fields.ci_id]]'
Пример шаблона, создающего SNMP метрику по списку модулей, определенных в переменной modules. Сами модули, с перечислением OID описаны в настройке экспортера.
[% set modules = ['generic','if_mib','tcp-connections'] %]
[% for module in modules %]
- labels:
ci_id: [[fields.ci_id]]
module: '[[module]]'
ci_name: '[[fields.ci_name]]'
ci_type_name: [[fields.ci_type_name]]
community: public
version: 2c
metric_name: [[fields.metric_name]]
template_name: [[fields.template_name]]
targets:
- '[[attributes.hsm_ip_address]]:161'
[% endfor %]
Описание структуры:
targets: Список таргетов, которые Prometheus будет сканировать. Каждый таргет указывается в форматеадрес:порт.labels: Метки (labels), которые будут добавлены ко всем таргетам в этой группе. Метки используются для фильтрации и группировки метрик.
Для доступа к атрибутам КЕ в шаблоне можно использовать ключевые поля.
Работа со связанными узлами
Система Памир реализует продвинутый механизм работы со связанными конфигурационными единицами (КЕ), который автоматически определяет и учитывает иерархические связи между объектами без необходимости явного указания связей в запросах.
Автоматическое определение связанности
-
Непересекающиеся деревья:
- Памир воспринимает каждую независимую иерархию КЕ как отдельное дерево
- Система автоматически определяет принадлежность листьев к конкретным корневым узлам
- Исключается возможность перемешивания КЕ из разных деревьев
-
Механизм разрешения связей:
- При обработке шаблона система анализирует все ссылки на атрибуты
- Для каждого узла (tql_node_N) определяется его положение в иерархии
- Устанавливаются действительные связи между указанными узлами в контексте конкретного дерева
Синтаксис ссылок на атрибуты
Ссылки на атрибуты связанных узлов оформляются в виде:
[[tql_node_1.attributes.hostname]]
[[tql_node_2.fields.ci_id]]
Где:
tql_node_N- идентификатор узла в TQL-запросеattributes- указание на атрибуты КЕfields- указание на системные поля КЕhostname- конкретный атрибутci_id- конкретное поле
Пример работы с иерархиями
Рассмотрим пример инфраструктуры с двумя независимыми деревьями:
Дерево 1:
Корень: DC1 (тип: Datacenter)
├── RACK1 (тип: Rack)
│ ├── ESX1 (тип: Host)
│ └── ESX2 (тип: Host)
└── RACK2 (тип: Rack)
└── ESX3 (тип: Host)
Дерево 2:
Корень: DC2 (тип: Datacenter)
├── RACK3 (тип: Rack)
│ ├── ESX4 (тип: Host)
│ └── ESX5 (тип: Host)
└── RACK4 (тип: Rack)
└── ESX6 (тип: Host)
TQL-запрос
Шаблон таргета
location: "[[Datacenter_1.attributes.name]]",
rack: "[[Rack_2.attributes.name]]",
host: "[[Host_3.attributes.name]]"
Ключевые особенности:
-
Автоматическое разрешение связей:
- Памир самостоятельно определяет путь от листа (Host) к корню (Datacenter) через промежуточные узлы (Rack)
- Для ESX1 будут использованы DC1 и RACK1, для ESX4 - DC2 и RACK3
-
Гарантия целостности деревьев:
- Невозможно случайное смешение атрибутов из разных деревьев
- Например, ESX1 никогда не будет связан с DC2 или RACK3
-
Оптимизация запросов:
- Система кэширует пути связей между КЕ
- При массовой обработке минимизируется количество обращений к CMDB
-
Множественные связи: Если КЕ связана с несколькими узлами, то эти узлы будут перечислены черех
|:ESX4|ESX5Разделитель можно изменить с помощью функции
join(","):[[Host_3.attributes.name | join(",")]]Результат:
ESX4,ESX5
Обработка ошибок и крайние случаи
- Отсутствующие связи:
- Если указанная связь не существует, атрибут считается неопределённым
- Рекомендуется использовать значения по умолчанию:
set_if_not_value,skip_if_not_value.